My 25 billion benchmark:
Code:
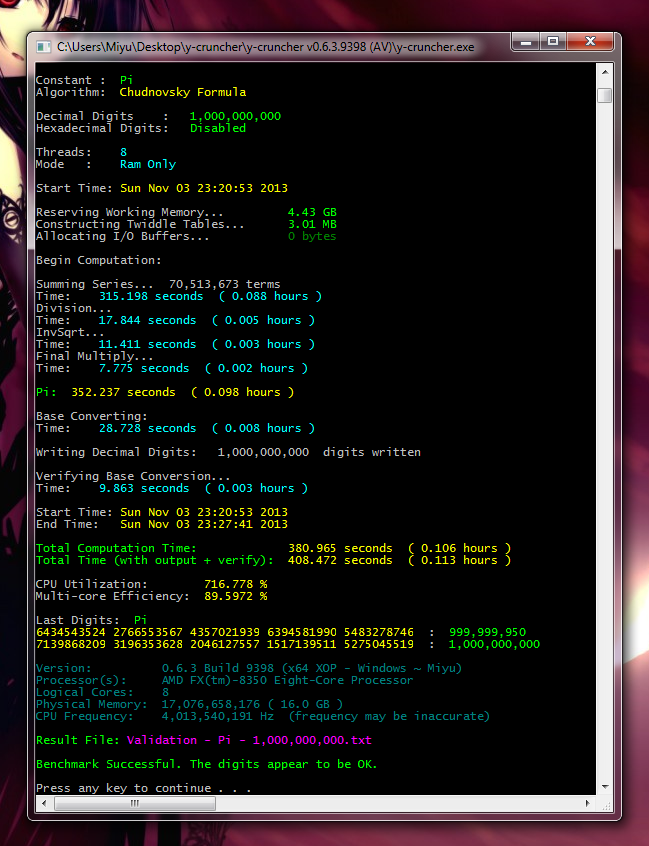
Constant : Pi
Algorithm: Chudnovsky Formula
Decimal Digits : 25,000,000,000
Hexadecimal Digits: Disabled
Threads: 32
Mode : Ram Only
Start Time: Wed Mar 12 18:44:01 2014
Reserving Working Memory... 117 GB
Constructing Twiddle Tables... 4.38 MB
Allocating I/O Buffers... 0 bytes
Begin Computation:
Summing Series... 1,762,841,738 terms
Time: 7730.888 seconds ( 2.147 hours )
Division...
Time: 240.249 seconds ( 0.067 hours )
InvSqrt...
Time: 156.062 seconds ( 0.043 hours )
Final Multiply...
Time: 104.593 seconds ( 0.029 hours )
Pi: 8231.793 seconds ( 2.287 hours )
Base Converting:
Time: 329.628 seconds ( 0.092 hours )
Writing Decimal Digits: 25,000,000,000 digits written
Verifying Base Conversion...
Time: 154.667 seconds ( 0.043 hours )
Start Time: Wed Mar 12 18:44:01 2014
End Time: Wed Mar 12 21:11:31 2014
Total Computation Time: 8561.420 seconds ( 2.378 hours )
Total Time (with output + verify): 8850.835 seconds ( 2.459 hours )
CPU Utilization: 1658.35 %
Multi-core Efficiency: 51.8234 %
Last Digits: Pi
2448547079 5329693979 7145627081 9204187454 9483487803 : 24,999,999,950
1309759846 5364560010 7388984278 8403481193 9913806533 : 25,000,000,000
Version: 0.6.3 Build 9416b (fix 1) (x64 AVX - Linux ~ Hina)
Processor(s): Genuine Intel(R) CPU @ 2.60GHz
Logical Cores: 32
Physical Memory: 203,221,774,336 ( 189 GB )
CPU Frequency: 2,600,380,032 Hz (frequency may be inaccurate)
Result File: Validation - Pi - 25,000,000,000.txt
Benchmark Successful. The digits appear to be OK.
And I started this up:
I don't know if I will actually let it run though:
Code:
Current Settings: (select option # to change setting)
1 Constant: Pi
2 Algorithm: Chudnovsky Formula
3 Decimal Digits: 13,300,000,000,000
4 Hexadecimal Digits: 11,045,410,915,501
5 Multi-Threading: 32 threads
6 Write Digits To: /data/pi
7 Compress Output: Yes - Compress digits and split them into multiple
files with 100,000,000,000 digits per file.
8 Computation Mode: Swap Mode
9 View Swap Configuration
10 Change Swap Configuration
11 Run I/O Benchmark
12 Min I/O Size: 32.0 MB per smallest unit. ( 32.0 MB global )
13 Memory Needed: 179 GB ( Minimum = 156 MB )
Disk Needed: 70.5 TB + 10.1 TB for output
0 Start Computation!
option: 0
Constant : Pi
Algorithm: Chudnovsky Formula
Decimal Digits : 13,300,000,000,000
Hexadecimal Digits: 11,045,410,915,501
Threads: 32
Mode : Swap Mode
Start Time: Wed Mar 12 21:30:19 2014
Reserving Working Memory... 179 GB
Constructing Twiddle Tables... 82.2 MB
Allocating I/O Buffers... 64.0 MB
Begin Computation:
Summing Series... 937,831,802,335 terms
Summing: 0% ( 32 ) -> ( 4,454,943,452 )
Curious to see how bad performance hits when it starts having to hit the disk on linux. I don't know why CPU usage would have been a problem with O_DIRECT since DD writing even at 1 Gbyte/sec is <20% of a core when using direct I/O.







 Reply With Quote
Reply With Quote ive got a question for ya. what do you think of a C6100 8xL5520@2.6 with 96gb of ram
ive got a question for ya. what do you think of a C6100 8xL5520@2.6 with 96gb of ram  ive got one inbound for a late Dec delivery and wanted to have some fun with it before i deidicate it to 24/7 boinc
ive got one inbound for a late Dec delivery and wanted to have some fun with it before i deidicate it to 24/7 boinc

















Bookmarks