




Here's a little something interesting...
I ran some automated benchmarks on my Lan-Box to see how the new version scales with multiple cores.
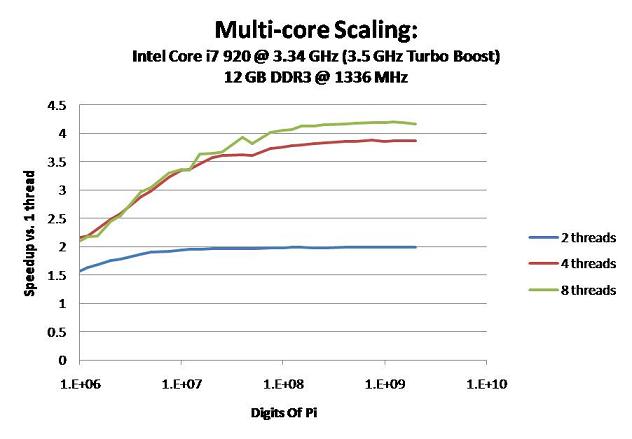
Here are the results: Main Page
The graph shows how many times faster a multi-threaded run is than a single-threaded run.
Obviously, 2 threads cannot do any better than 2x improvement and 4 threads cannot do better than 4x.
When the computation is small, the amount of time spawning threads dominates actual computation time. Therefore it scales very poorly for small computations. The bigger you go, the better it scales.
Notice that below ~5 million digits, Hyper-Threading with 8 threads is slower than 4 threads without HT. This is because the benefits of HT is outweighed by the overhead of spawning double the threads.
So if you have an i7 and you want to get the fastest 1M, 2M, or 4M times, try disabling HT...
This wasn't the case in the older versions. Because of a number of optimizations and bug-fixes, v0.4.1 doesn't scale as well as the older versions for small computations. (But it scales slightly better for large computations.)

 Reply With Quote
Reply With Quote

Bookmarks