Seems legit. :p
Code:
Validation Version: 1.1
Program: y-cruncher - Gamma to the eXtReMe!!! ( www.numberworld.org )
Copyright 2008-2011 Alexander J. Yee ( a-yee@u.northwestern.edu )
User: "Username.txt" Not found.
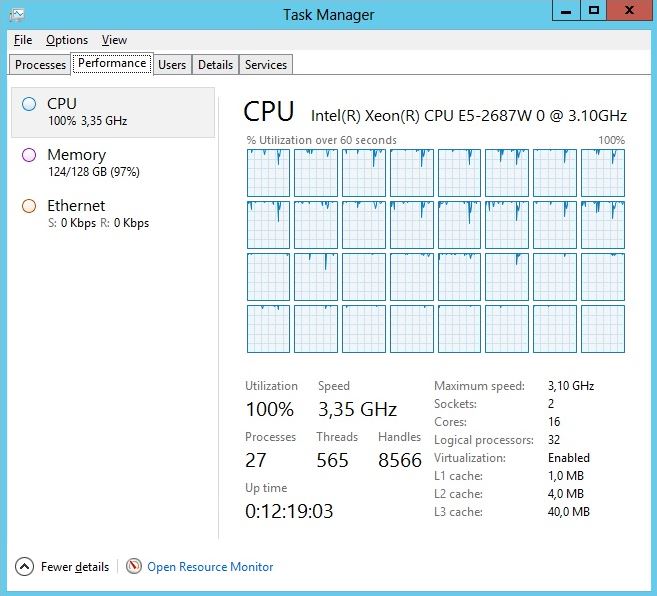
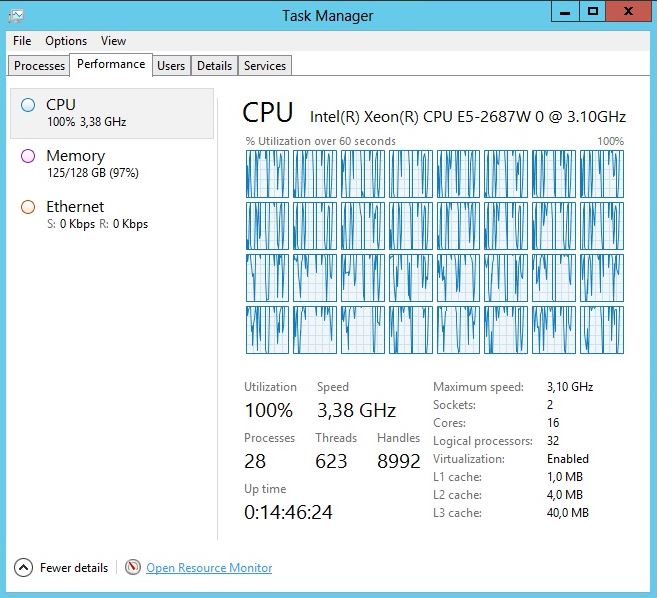
Processor(s): AMD FX(tm)-8350 Eight-Core Processor
Logical Cores: 8
Physical Memory: 34,277,138,432 bytes ( 32.0 GB )
CPU Frequency: 4,966,812,719 Hz
Program Version: 0.5.5 Build 9180 (fix 2) (x64 SSE3 - Windows ~ Kasumi)
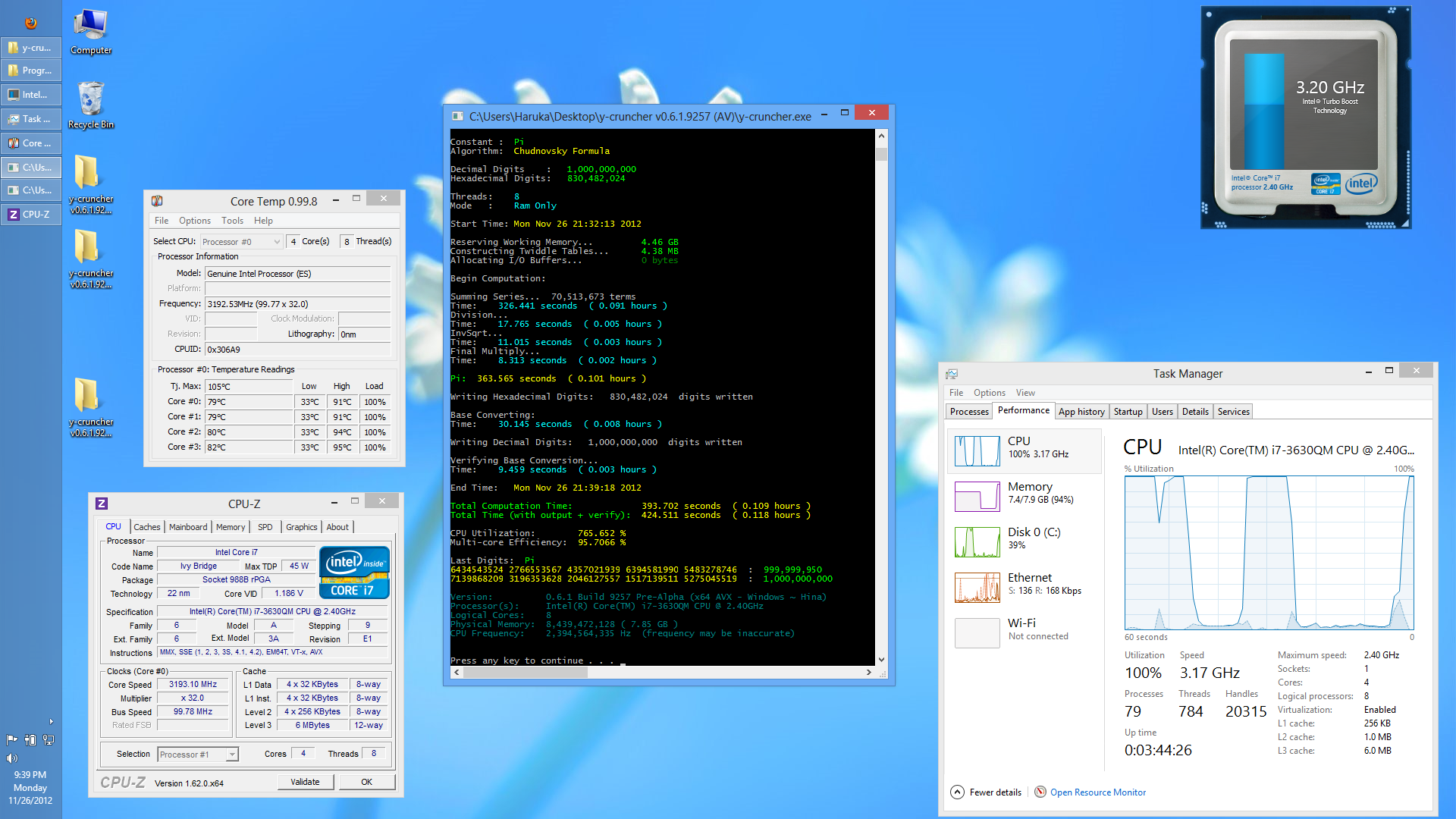
Constant: Pi
Algorithm: Chudnovsky Formula
Decimal Digits: 250,000,000
Hexadecimal Digits: Disabled
Threading Mode: 8 threads
Computation Mode: Ram Only
Swap Disks: 0
Working Memory: 1.26 GB
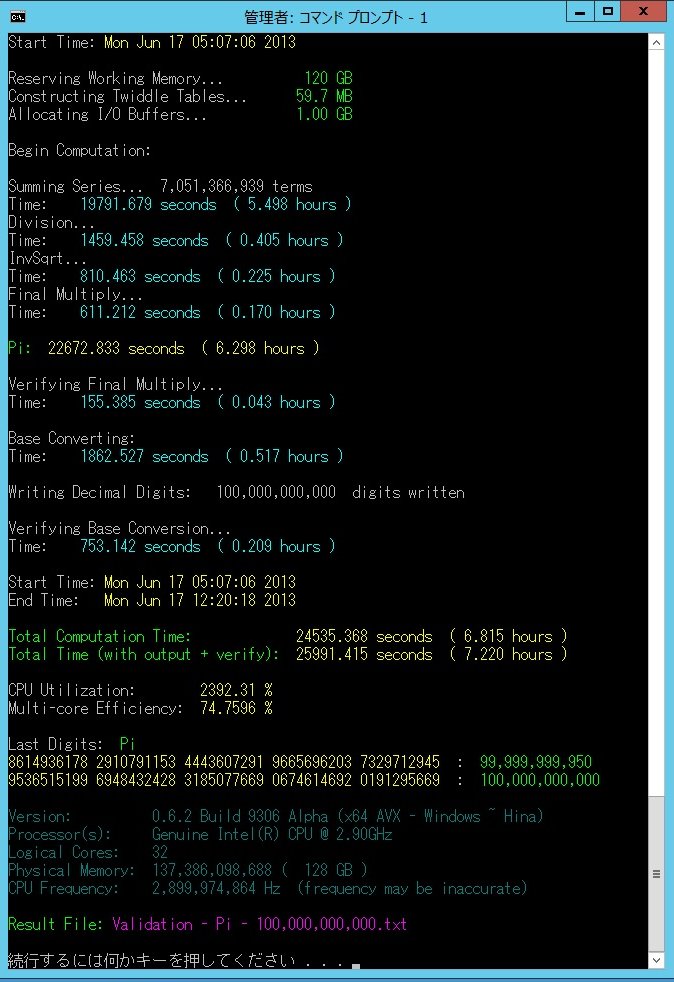
Start Date: Thu Jan 31 19:52:58 2013
End Date: Thu Jan 31 19:54:21 2013
Computation Time: 18,446,744,073,709,551,612.000 seconds
Total Time: 3.348 seconds
CPU Utilization: 4294953646.4294967261 %
Multi-core Efficiency: 4294965590.4294967267 %
Last Digits:
3673748634 2742427296 0219667627 3141599893 4569474921 : 249,999,950
9958866734 1705167068 8515785208 0067520395 3452027780 : 250,000,000
Timer Sanity Check: Failed
Frequency Sanity Check: Passed
ECC Recovered Errors: 0
Checkpoint From: None
----
Checksum: 1d89c9bd846a006b012285b80aef0b399978278f8a7958e7151bddf94081ce3c





Originally Posted by st0ned


 ? I mean to support AVX on windows 8 :P
? I mean to support AVX on windows 8 :P
 Reply With Quote
Reply With Quote








 to a true gentleman..
to a true gentleman..


Bookmarks