

what happened to saaya lately ????



what happened to saaya lately ????
WILL CUDDLE FOR FOOD
Originally Posted by JF-AMD


http://citavia.blog.de/2010/11/08/la...t-day-9933368/
Ok, the salt was worth 3 sqmm
Well, we do know it is smaller than a Lisbon die.
This may be completely off base but it sounds to me that bulldozer is virtually just two bobcats fused together but sharing Micro-code and the floating point unit.
Fast computers breed slow, lazy programmers
The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay.
http://www.lighterra.com/papers/modernmicroprocessors/
Modern Ram, makes an old overclocker miss BH-5 and the fun it was
The problem with above statement is that Bobcat is actually slower per core than 10h while BD is faster. There are some similarities but overall they are not comparable(die size difference per core is one big indicator).
No, they are completely different cores designed by completely different teams.
IF you think that +30% is not significant, then all intel processors since Core2 are "unimpressive" ;-)
I meant the same think, AMD could recycle their triple channel C42 (or whatever the name is) platform, too. But even that costs money, not sure how many board manufacturers would build boards for it.of course not... thats why you dont do a platform for ocers but recycle one like intel did...
Well - it will depend heavily on the chip .. if it is fast enough, AMD would snatch lots of that small enthusiast market segment. But it will be hard against Intel's 22nm CPUs.
Why should nVidia's problem be of AMD's concern ? If it would have been ATi - then you could make at least a small connection .. but nVidia ?of course not, but isnt there something in between? at the edge is good, but right at the edge... im just saying after reading about all that whisker stuff and thermal stress on solder balls with memory chips (worked for a module house) it looks like a possible problem to me... especially thinking of nvidias bumpgate disaster in the past few years...
With the same statement you could argue that a Corvette car with an 8 cylinder is just two Toyota Prius with 4 cylinders fused together .. does it make sense ? ;-)
comparing a corvette to a prius? im pretty sure ive killed for less
also the improvement of the memory bandwidth with duel channel also reduces the server cost for people who need high speed, now do it with 33% less ram sticks. sounds like a good deal to me.
2500k @ 4900mhz - Asus Maxiums IV Gene Z - Swiftech Apogee LP
GTX 680 @ +170 (1267mhz) / +300 (3305mhz) - EK 680 FC EN/Acteal
Swiftech MCR320 Drive @ 1300rpms - 3x GT 1850s @ 1150rpms
XS Build Log for: My Latest Custom Case
That is the thing, AMD is currently on a multi-core/multi-threaded direction and the logical step is not to pursue single thread performance. Rather to aim for the single thread sweet spot and hit Intel with simply a much more efficient design. Now there may be prefetch and prediction enhancements but besides that; I really don't logically see anything different beyond the sharing in the front end and in the FPU. I admit I'm probably wrong but it is certainly something to ponder.
Fast computers breed slow, lazy programmers
The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay.
http://www.lighterra.com/papers/modernmicroprocessors/
Modern Ram, makes an old overclocker miss BH-5 and the fun it was
lol every single piece in the BD architecture is at least 2 times stronger than on bobcat, front end of a bd module is 4 times wider than a bobcat core; integer cores are 2 times more powerful (make that 4 times for each core in a BD module), FPU is more than doubled with more functions; memory controller is at least 3 times faster than on bobcat (dual 1866 vs single 1066 with additional improcement), L3 cache is present; more L2 cache, better process and platform
a bd module is significantly more than just 2 bobcat cores slapped together...
Core i7 2600k|HD 6950|8GB RipJawsX|2x 128gb Samsung SSD 830 Raid0|Asus Sabertooth P67
Seasonic X-560|Corsair 650D|2x WD Red 3TB Raid1|WD Green 3TB|Asus Xonar Essence STX
Core i3 2100|HD 7770|8GB RipJawsX|128gb Samsung SSD 830|Asrock Z77 Pro4-M
Bequiet! E9 400W|Fractal Design Arc Mini|3x Hitachi 7k1000.C|Asus Xonar DX
Dell Latitude E6410|Core i7 620m|8gb DDR3|WXGA+ Screen|Nvidia Quadro NVS3100
256gb Samsung PB22-J|Intel Wireless 6300|Sierra Aircard MC8781|WD Scorpio Blue 1TB
Harman Kardon HK1200|Vienna Acoustics Brandnew|AKG K240 Monitor 600ohm|Sony CDP 228ESD
ok let us look at what has already been published.
Note that the integer units are very similar but bulldozer includes more flexible load/store logic.
Also note that the front end of bulldozer is exactly double that of bobcat.
Things such as Cache size and implementation are any argument against my idea; nor is the memory performance or implementation that radical of a change. [AMD has done it dozens of times with K8]
Also, I must mention that I am not suggesting that they just "slapped" two bobcats together. Rather that the integer units are rather bobcat derived and focus on performance per transistor rather than maximum performance.
And if I am correct, then the Bulldozer cores should not be more than 40% larger than K8. That is my prediction and my explanation for it; the validity can only be proven or disproved by AMD.
Fast computers breed slow, lazy programmers
The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay.
http://www.lighterra.com/papers/modernmicroprocessors/
Modern Ram, makes an old overclocker miss BH-5 and the fun it was
hmmm but does 1mb really boost ipc that much?
the highest gains from bigger caches in the past ive seen were around 5%...
funny btw, instead of adding cache to a design as a "midlife kicker" its now adding cores+cache
hah, yeah but not many people run their mem below 2000, and if they do they usually run it at tight timings boosting bw :P
hmmm so they CAN share their fpu but dont always? but then how does this affect the definition of a core? its still two cores then, just that they CAN in some scenarios work together... right?
well the presentation somebody posted here only mentions a 30% boost while mentioning a 20% boost in supported memory clocks... call me cynical but in my experience with presentations like this it doesnt mean 20% clockspeed resulting bw boost PLUS 30% arch resulting boost... it means 20% clockspeed resulting bw boost plus 10% arch resulting boost... BEST CASE SCENARIO
my bad
cause i actually like amd, and i think you guys can do a lot better than what youve been doing in the past years...
amds ddr2 and ddr3 imcs aree... no offense, but seriously... the ddr2 imc offered no advantages over ddr1 whatsoever, and the ddr3 imc had clockspeed issues from day1 and is comparable to intels P35/X38 ddr3 memory controller which is 2, soon 3 generations behind.
the only memory controller amd ever had that rocked was the a64 imc, and, correct me if im wrong, was mostly the brainchild of a single brilliant engineer, which left the company, so turning that into a "history of achievements of amd" is a pretty far stretch dont you think?
you mentioned that before... ive never seen people complain about "small" caches on amd chips... not here on xs at least, people here tend to compare performance, not specs...
and when people DID complain about cache sizes, you should know that they dont complain about cache sizes, what they really want to say is "i want a faster cpu"
thats what i said...
so then why did somebody mention that with BD the definition of cores changes? thats what started the whole thing, it seems it was a misunderstanding? it made me think 2 bulldozer cores can actually only work in tandem and not chew through data on their own, which would make it ONE core and not two. several people then hooked in and disagreed that such a core would still be two cores for some reason.
i guess it was misunderstandings all over the place
as long as each part CAN work fully independantly, no... as soon as two blocks are dependant on each other its ONE block... at least by my definition
thx for clarifying this
1. good for them... whats it supposed to be to me?
2. i cant believe you think i dont know that, i think we both know that you know that i know it ^^
3. not my intention... the one fpu per module was a misunderstanding, my bad...
thx for contributing to the discussion
but they do share the same building blocks right? some of them at least... makes sense...
i thought we are talking about memory bandwidth, not ipc or overall performance...
if bd has a 30% ipc or overall performance boost (per core) over their current chips ill be deeply impressed :0
amd has a tripple channel platform?
wasnt it quad channel? its MCM so its two dualchannel chips on one package. and they ARE recycling that for servers and might use it for enthusiasts, though i doubt it... enthusiasts wont see benefits from the extra bandwidth i think... for enthusiasts latency is more important than bandwidth cause only few cores are actually used.
sigh... cause they all use solder balls to connect silicon to organic packages? :P

sayya: no, IMC on Thuban is not
ROG Power PCs - Intel and AMD
CPUs:i9-7900X, i9-9900K, i7-6950X, i7-5960X, i7-8086K, i7-8700K, 4x i7-7700K, i3-7350K, 2x i7-6700K, i5-6600K, R7-2700X, 4x R5 2600X, R5 2400G, R3 1200, R7-1800X, R7-1700X, 3x AMD FX-9590, 1x AMD FX-9370, 4x AMD FX-8350,1x AMD FX-8320,1x AMD FX-8300, 2x AMD FX-6300,2x AMD FX-4300, 3x AMD FX-8150, 2x AMD FX-8120 125 and 95W, AMD X2 555 BE, AMD x4 965 BE C2 and C3, AMD X4 970 BE, AMD x4 975 BE, AMD x4 980 BE, AMD X6 1090T BE, AMD X6 1100T BE, A10-7870K, Athlon 845, Athlon 860K,AMD A10-7850K, AMD A10-6800K, A8-6600K, 2x AMD A10-5800K, AMD A10-5600K, AMD A8-3850, AMD A8-3870K, 2x AMD A64 3000+, AMD 64+ X2 4600+ EE, Intel i7-980X, Intel i7-2600K, Intel i7-3770K,2x i7-4770K, Intel i7-3930KAMD Cinebench R10 challenge AMD Cinebench R15 thread Intel Cinebench R15 thread
exactly, thats why amd imc is so good.. due low latency.. they like very tight mem timings. I dont put weght much on bandwidth, it is like compare SSD and harddrives without attention for load times.
Moderately clocked Athlon 2 has lower mem latency than highly Oced I7 9xxcpu power is another thing.
Vishera 8320@ 5ghz | Gigabyte UD3 | 8gb TridentX 2400 c10| Powercolor 6850 | Thermalight Silver Arrow (bench Super KAZE 3k) | Samsung 830 128gbx2 Raid 0| Fractal case
BD vs Bobcat cache differences:
BD has 2MB of inclusive cache,running at core level clocks. Bobcat has 512KB per core,dedicated L2 cache,running at half the clock speed.
BD has 8MB of L3 running at 2.4+Ghz,victim cache(mostly exclusive),partitioned at 4 subcaches of 2MB each. Bobcat has no L3 at all.
As you can see,BD has many times more potent cache subsystem.Not only the clocks are 2x in the L2 part,but it's 4x bigger effectively(for single thread workload) and it has 8MB of L3 on it's disposal.
As for the rest of the memory subsystem:
BD can do 2 128bit loads and 1 128bit store per cycle,per core.Bobcat can do 1 64bit load and 1 64bit store per cycle. BD and Bobcat have "full" OoO load/store capabilities. BD effectively gas 2x better L/S BW versus Bobcat,per core.
The FPU can be dedicated per core or shared(by one or both cores). This means,that a 8 core Orochi can have 8 128bit FMAC units,meaning each core has its own FMAC.It also means that in single thread workloads one core can have 2 FMACs to itself,executing FMA ops or consecutive FADDs/FMULs which is not doable in today's designs.Versus Nehalem,in classical FP code,one 128bit FMAC is equal to 2 Nehalem "ports" of execution(per core Nehalem has 2 dedicated ports,one for ADD and one for MUL) in FP code,or even faster than that.If the serial code has consecutive FADDs/FMULs than one BD core can do 2 of these per clock,which is not possible in today's x86 designs.
hmmm so they CAN share their fpu but dont always? but then how does this affect the definition of a core? its still two cores then, just that they CAN in some scenarios work together... right?
30% is solely due to IMC logic improvement,while additional 20% is for clock speed improvement .well the presentation somebody posted here only mentions a 30% boost while mentioning a 20% boost in supported memory clocks... call me cynical but in my experience with presentations like this it doesnt mean 20% clockspeed resulting bw boost PLUS 30% arch resulting boost... it means 20% clockspeed resulting bw boost plus 10% arch resulting boost... BEST CASE SCENARIO
Yes ,each core can have one 128bit FMAC(doing work on FADD+FMUL in parallel).If the second FMAC is not used by the other core or AVX code is in use,one core uses both FMACs.as long as each part CAN work fully independantly, no... as soon as two blocks are dependant on each other its ONE block... at least by my definition
Just as two cars share the same building blocks,say engine,differential,gear box etcbut they do share the same building blocks right? some of them at least... makes sense...
30% was never mentioned IIRC. I don't think you will see that kind of a jump going to BD. 15% jump in int is more reasonable.Turbo comes on top of that.if bd has a 30% ipc or overall performance boost (per core) over their current chips ill be deeply impressed :0
One server platform featuring improved BD core and 10 cores per chip(non MCM) will have 3 channel IMC.In MCM though,the IMC will still be Quad Channel.amd has a tripple channel platform?
wasnt it quad channel? its MCM so its two dualchannel chips on one package. and they ARE recycling that for servers and might use it for enthusiasts, though i doubt it... enthusiasts wont see benefits from the extra bandwidth i think... for enthusiasts latency is more important than bandwidth cause only few cores are actually used.
That diagram is a speculation by Hiroshige Goto.It's not based on real BD or Bobcat but on scarce data we have today. Also one Bobcat core can retire 2 instructions per cycle while each BD core can do 4(be it int or fp).There's the huge difference.Also,Bobcat does not have unified integer scheduler
like BD does.Bobcat's FP resources are 4x less (BD module Vs 2 Bobcat cores).
Yes we talked about memory bandwidth, but I used the IPC as an example how differently your views are. You just stated it again... why is +30% IPC impressive, but not +30% Mem bandwith ?
Of course IPC is the overall number, and bandwidth has just a smaller influence on e.g. IPC. However, that does not make AMD's bandwidth achievements less impressive. +30% at the same mem speed is nothing to bother about, it is "for free" ... be happy about it.
Yes triple channel - planned for 2012- and no, no MCM. Maybe re-read the last pages ;-).amd has a tripple channel platform?
wasnt it quad channel? its MCM so its two dualchannel chips on one package.
Well enthusiasts are crazy about Intel's triple channel ... not sure if they have really benefits, but as long as they are crazy it is finethough i doubt it... enthusiasts wont see benefits from the extra bandwidth i think... for enthusiasts latency is more important than bandwidth cause only few cores are actually used.
So because Toyota has problems with their Prius, I should be worried about my Corvette, too, because both cars have 4 wheels to connect with the road ? Nice jokesigh... cause they all use solder balls to connect silicon to organic packages? :P
Last edited by Opteron146; 11-27-2010 at 05:19 AM.
Yes, they can share the FPU but they don't always. To get to 256-bit AVX, we share 2 FPU pipelines and Intel shares a 128-bit FPU with integer pipelines. In either case, to get to 256-bit AVX, you are sharing resources. We just choose to do it in a way that gives you 8 AVX units AND 16 integer pipelines. Intel does it in a way that gives you 8 AVX units and LESS THAN 8 integer untis (because some of their integer resources are going to handle the AVX instructions.)
If you look at the slide we specifically call out 50% throughput increase, one portion from improvements to the IMC and one portion because of higher speed memory.
I realize that you might not want to believe it, but if the slide spells that out specifically (and our lawyers approve all slides) then you can't create your own interpretation of the slide to downplay the performance increase.
Frequency doesn't matter. The efficency still sucks at AM3, even more than it sucked on AM2 when it was new.
Efficiency was awesome on AM2 compared to intel, what are you talking about?
Smile
you might want to note that most code does not mix fp and int heavily when using sse. this means that integer resources are not important when running fp heavy code so it's ok to share those ports. with BD, pure 256b fp will be half speed relative to non shared fpu's. oh and you may want to brush up on intel's nomenclature so you can describe their uarch in a more understandable way(SB isnt really sharing). they use execution ports for multiple instruction types and it's been that way since core2.
He has been ranting about AMD memory controllers for awhile, it has never made any sense.
BORIS: did u not seen practice change from IMC 940 Deneb to todays Thuban? I think, it is big diference at the "same" architecture
ROG Power PCs - Intel and AMD
CPUs:i9-7900X, i9-9900K, i7-6950X, i7-5960X, i7-8086K, i7-8700K, 4x i7-7700K, i3-7350K, 2x i7-6700K, i5-6600K, R7-2700X, 4x R5 2600X, R5 2400G, R3 1200, R7-1800X, R7-1700X, 3x AMD FX-9590, 1x AMD FX-9370, 4x AMD FX-8350,1x AMD FX-8320,1x AMD FX-8300, 2x AMD FX-6300,2x AMD FX-4300, 3x AMD FX-8150, 2x AMD FX-8120 125 and 95W, AMD X2 555 BE, AMD x4 965 BE C2 and C3, AMD X4 970 BE, AMD x4 975 BE, AMD x4 980 BE, AMD X6 1090T BE, AMD X6 1100T BE, A10-7870K, Athlon 845, Athlon 860K,AMD A10-7850K, AMD A10-6800K, A8-6600K, 2x AMD A10-5800K, AMD A10-5600K, AMD A8-3850, AMD A8-3870K, 2x AMD A64 3000+, AMD 64+ X2 4600+ EE, Intel i7-980X, Intel i7-2600K, Intel i7-3770K,2x i7-4770K, Intel i7-3930KAMD Cinebench R10 challenge AMD Cinebench R15 thread Intel Cinebench R15 thread
where did you find such proven details on Terramar and Sepang?
http://phx.corporate-ir.net/External...xUeXBlPTM=&t=1
Terramar and sepang are server products. don't try to draw conclusions about client products based on server.
 Posting Permissions
Posting Permissions


 Reply With Quote
Reply With Quote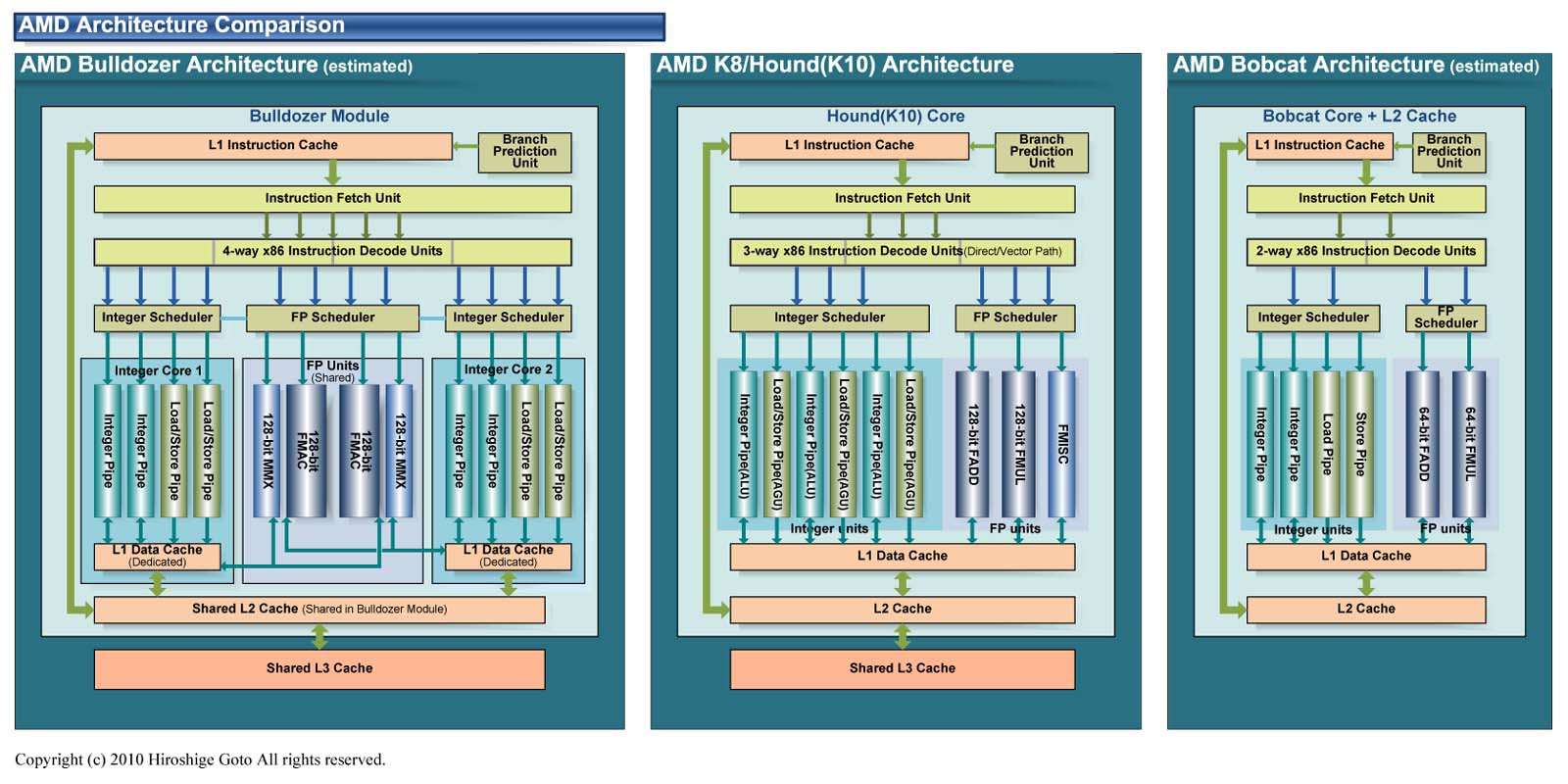




Bookmarks