




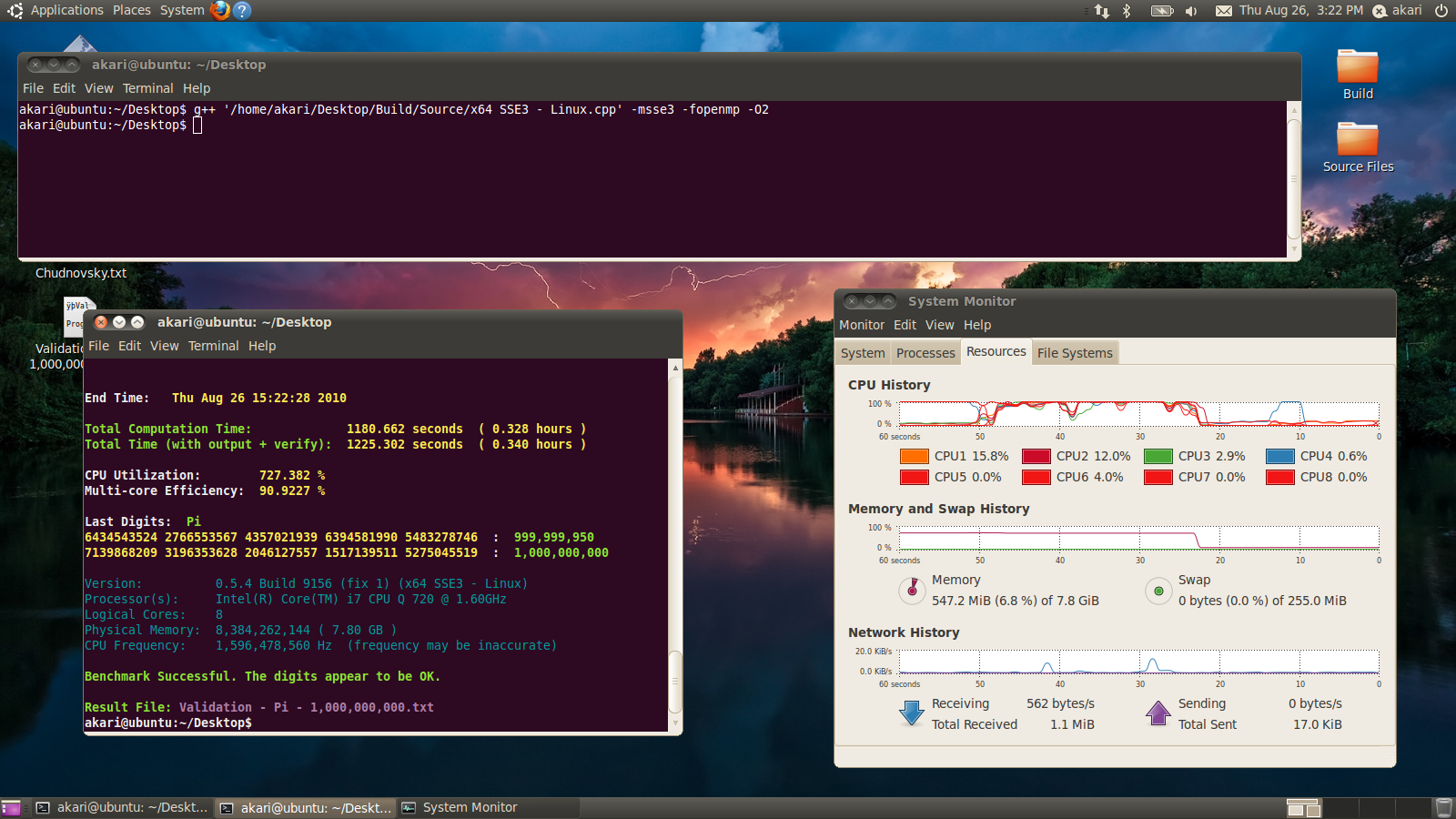
I know from past experience that O3 does a crazy amount of inlining. So I didn't want it to blow up on me the first time given the codesize of yc.
I'll play with it later.
EDIT:
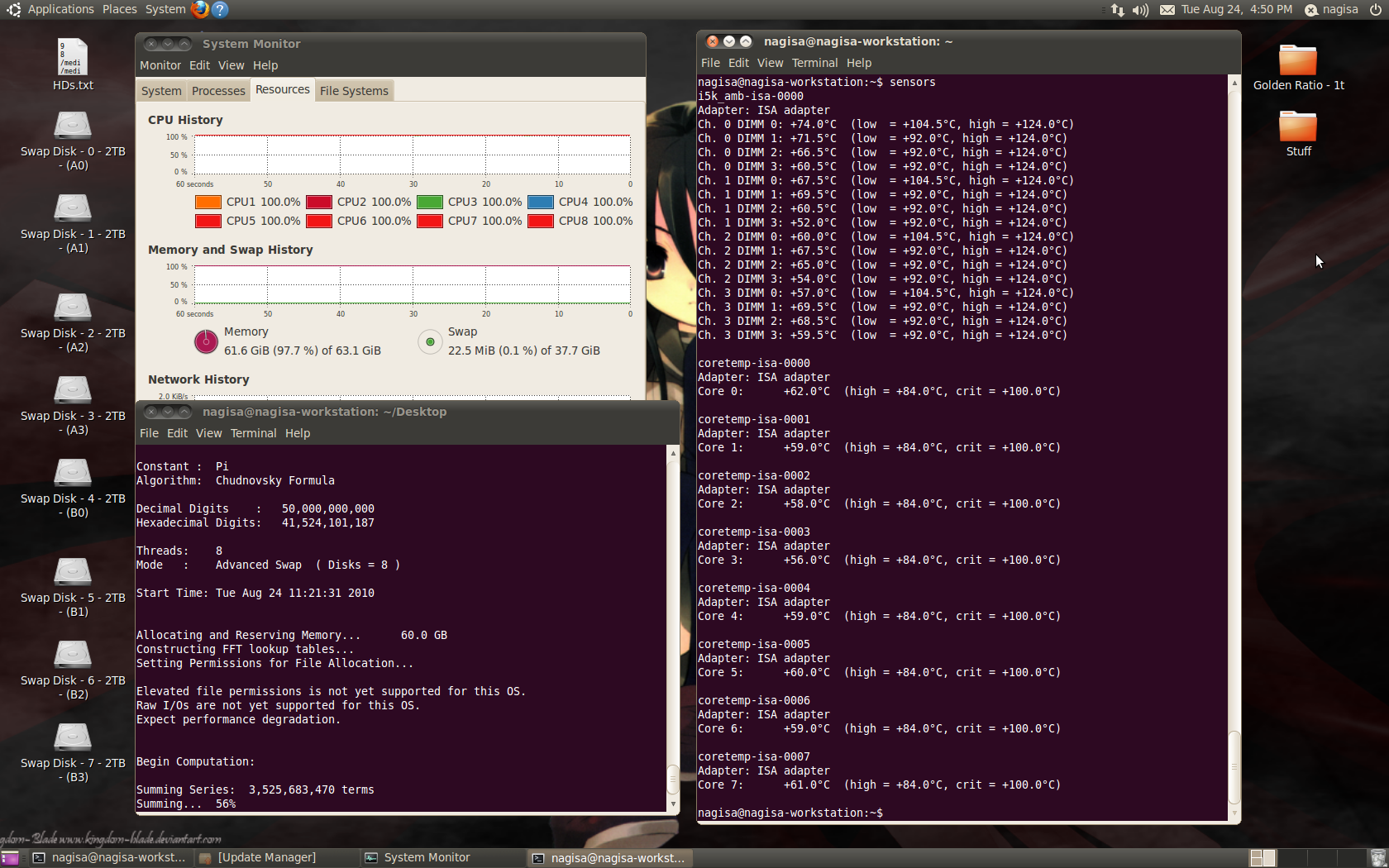
Found the source of why the validation files were all screwed up.
Linux uses 4 bytes for wchar_t...
Which makes it inherently incompatible with Windows... Not sure what I'm gonna do.

 Reply With Quote
Reply With Quote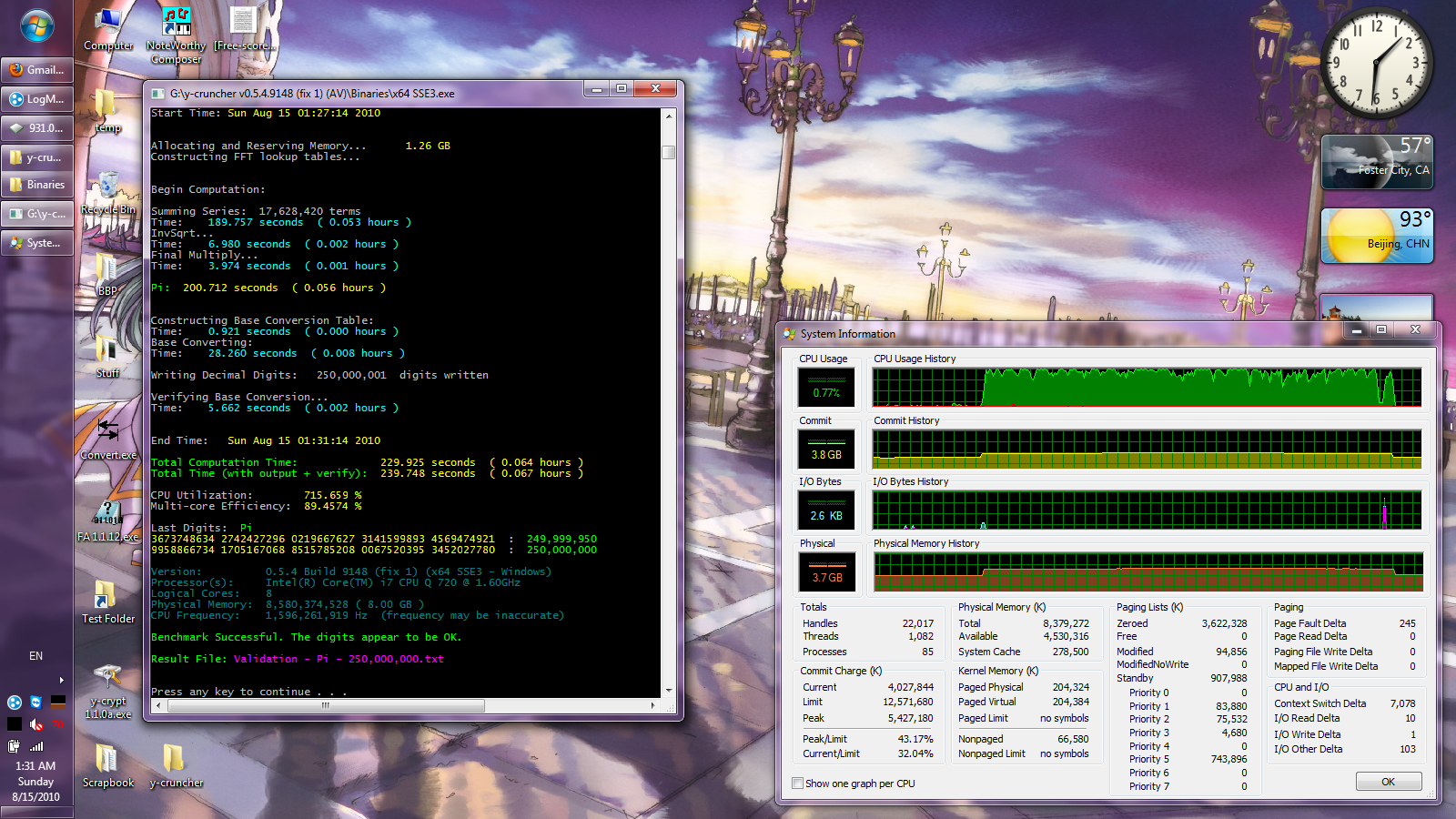
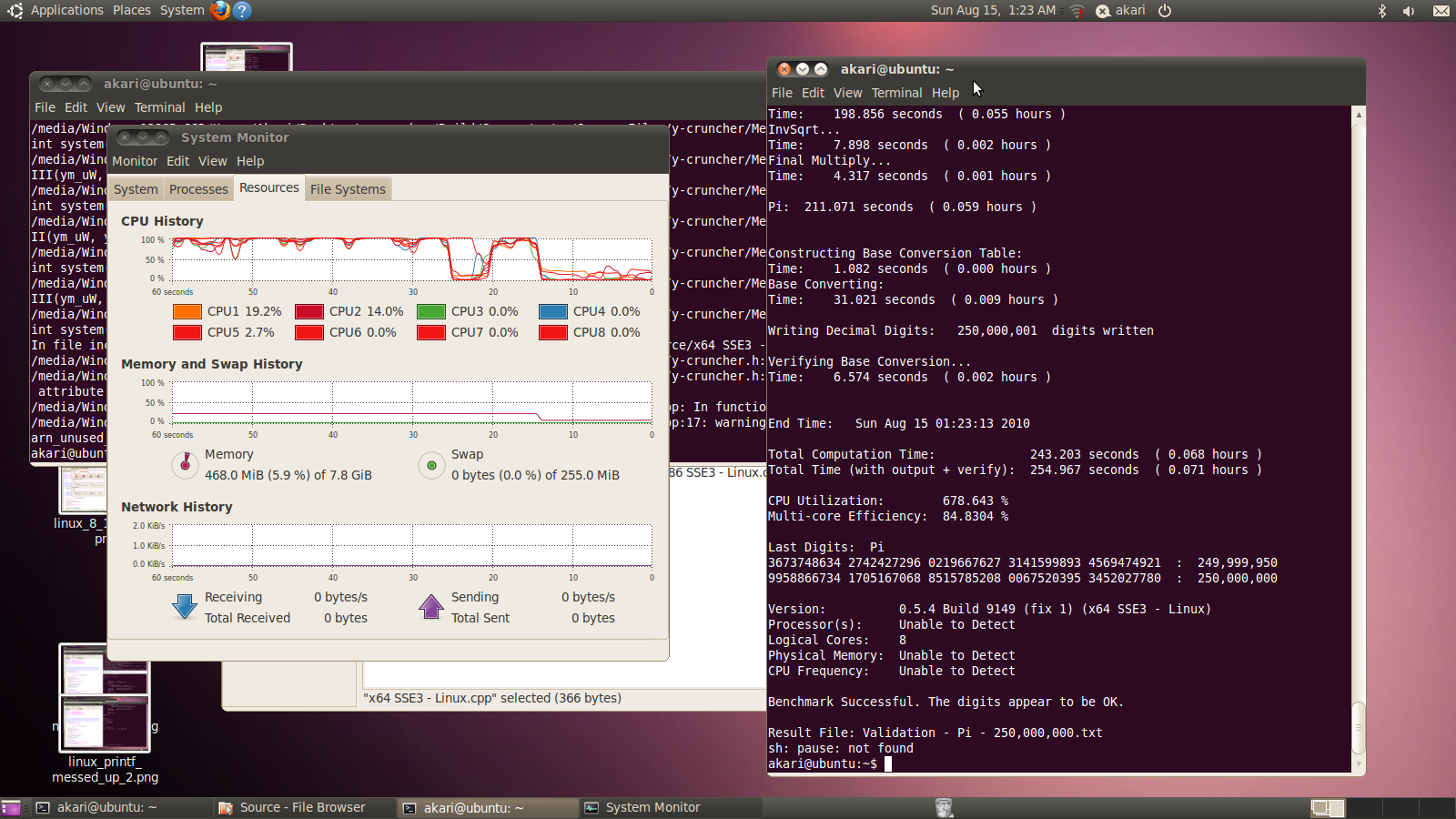
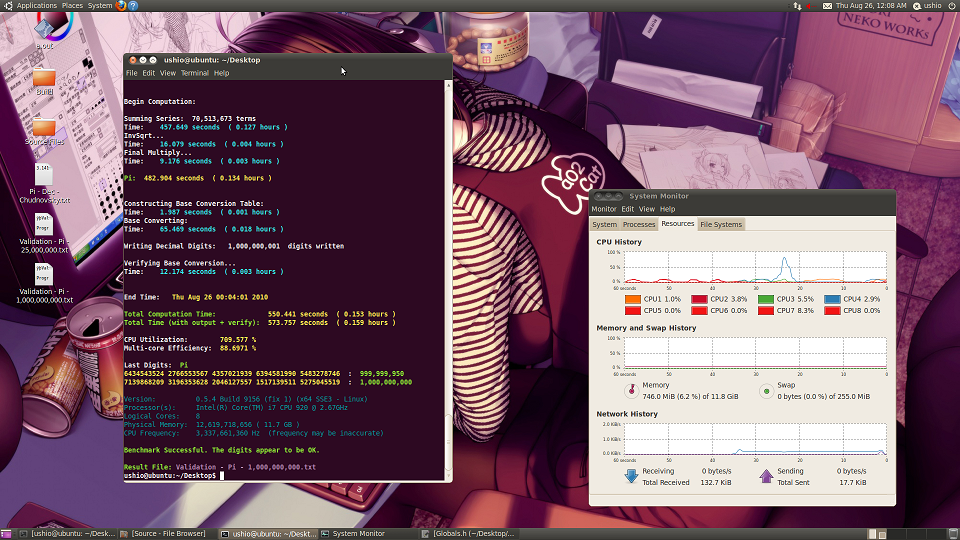
 So hopefully it won't be too long.
So hopefully it won't be too long. 










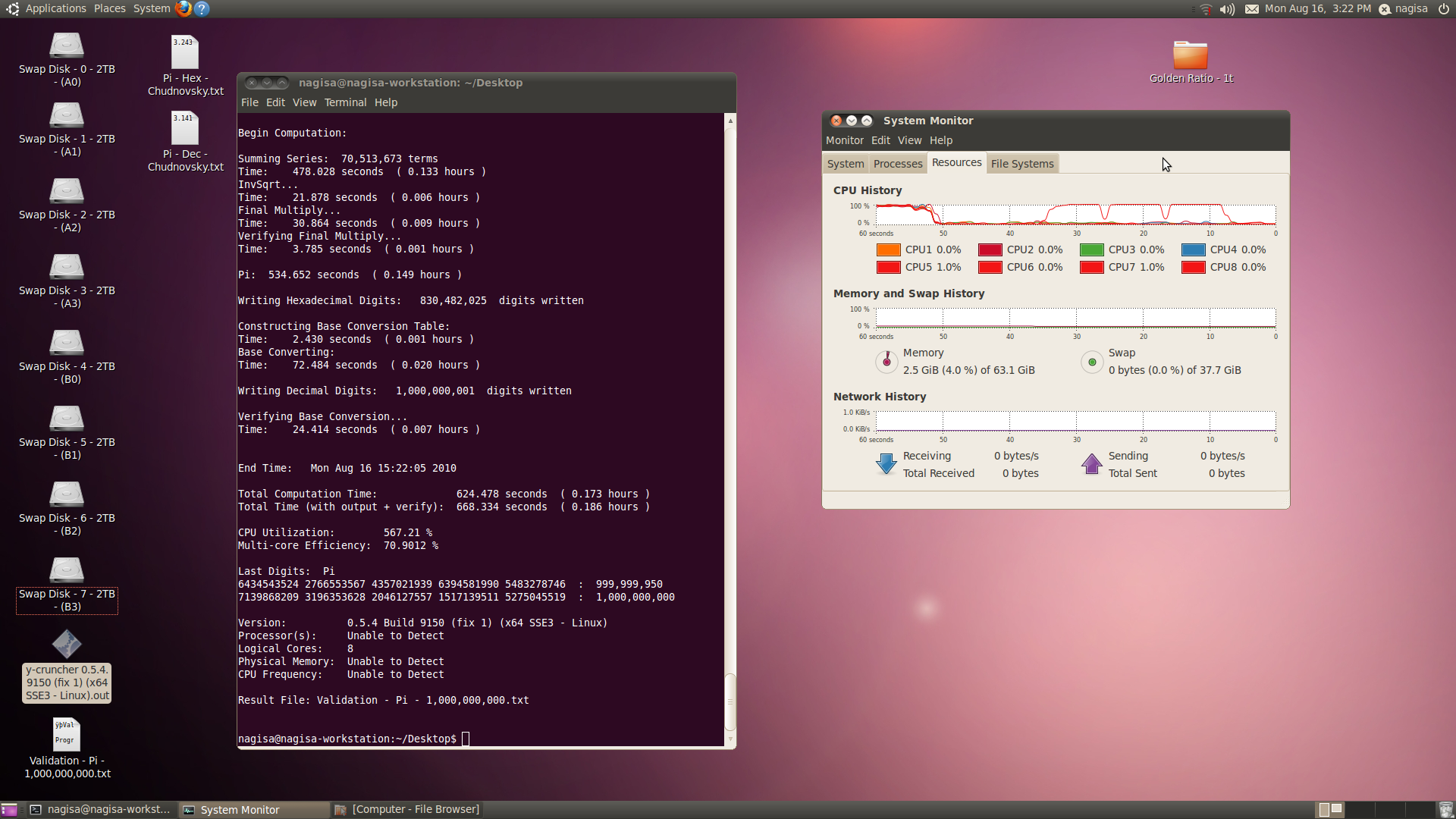
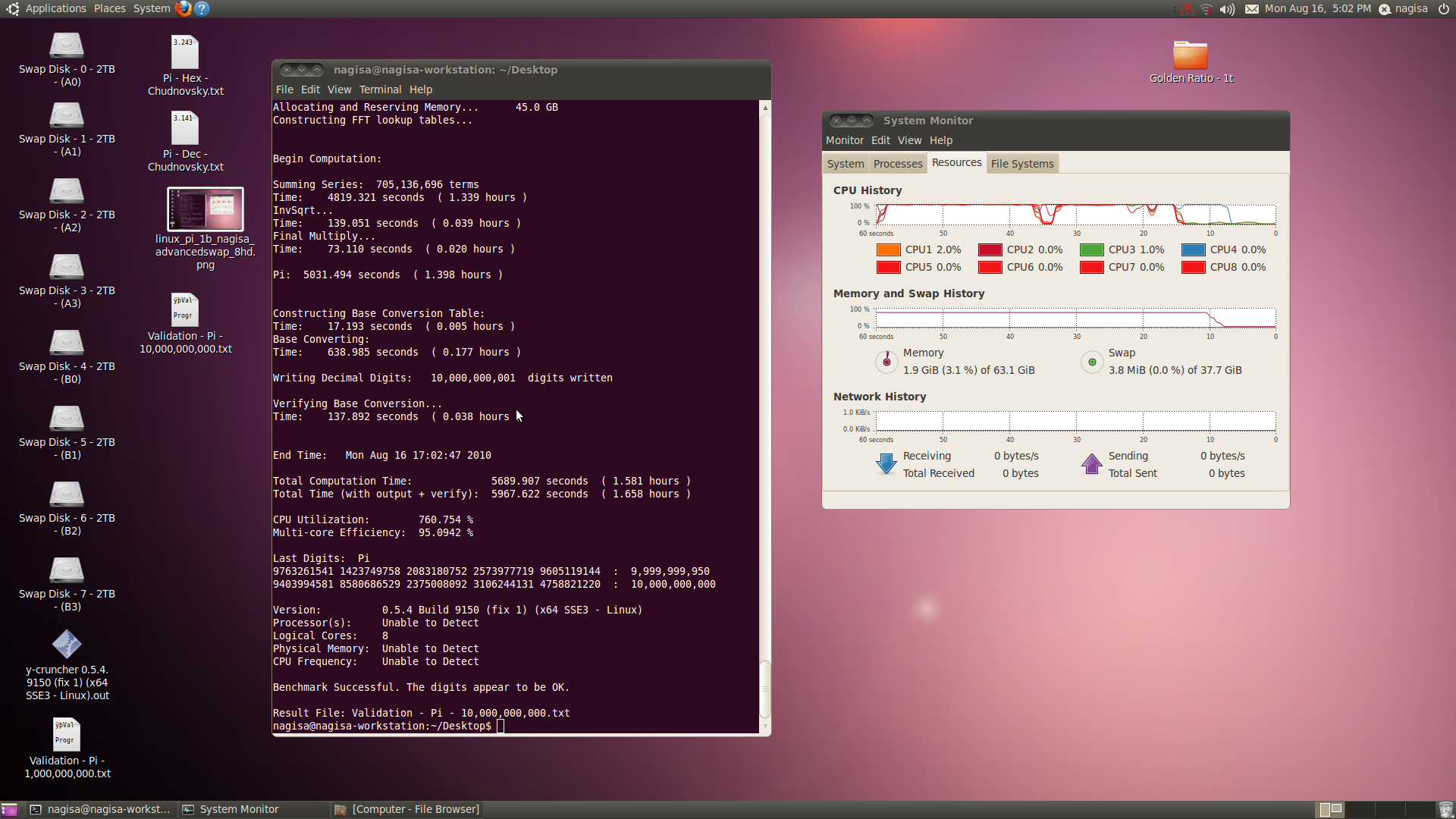










![Send a message via AIM to [XC] gomeler](images/misc/im_aim.gif)

 )
)



Bookmarks