



Agreed, bobcat is about 1/10th the complexity of BD.Originally Posted by informal

Not sure about "a while now". In the best case interpretation of the CC remarks (that they concerned llano + bobcat as opposed to llano desktop + llano mobile), we know they had internal samples of bobcat at the time of the CC, from which they are "learning a lot." They did not say how long they have had such samples, at least not in the CC.

 Reply With Quote
Reply With Quote






 , next month, fpt
, next month, fpt 


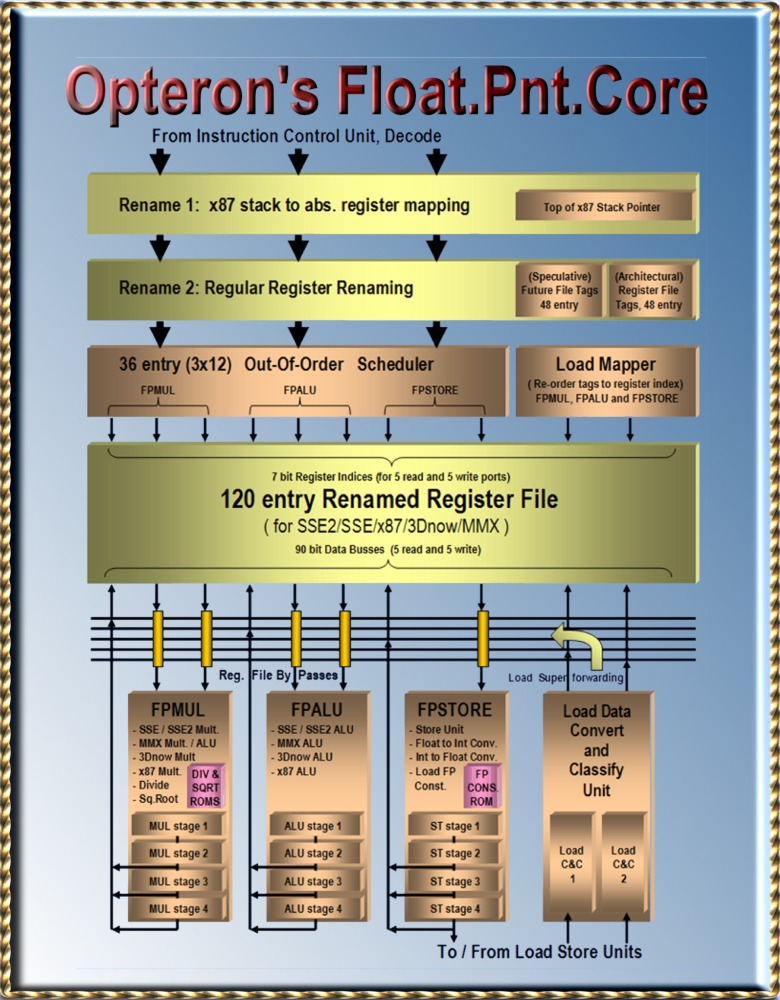
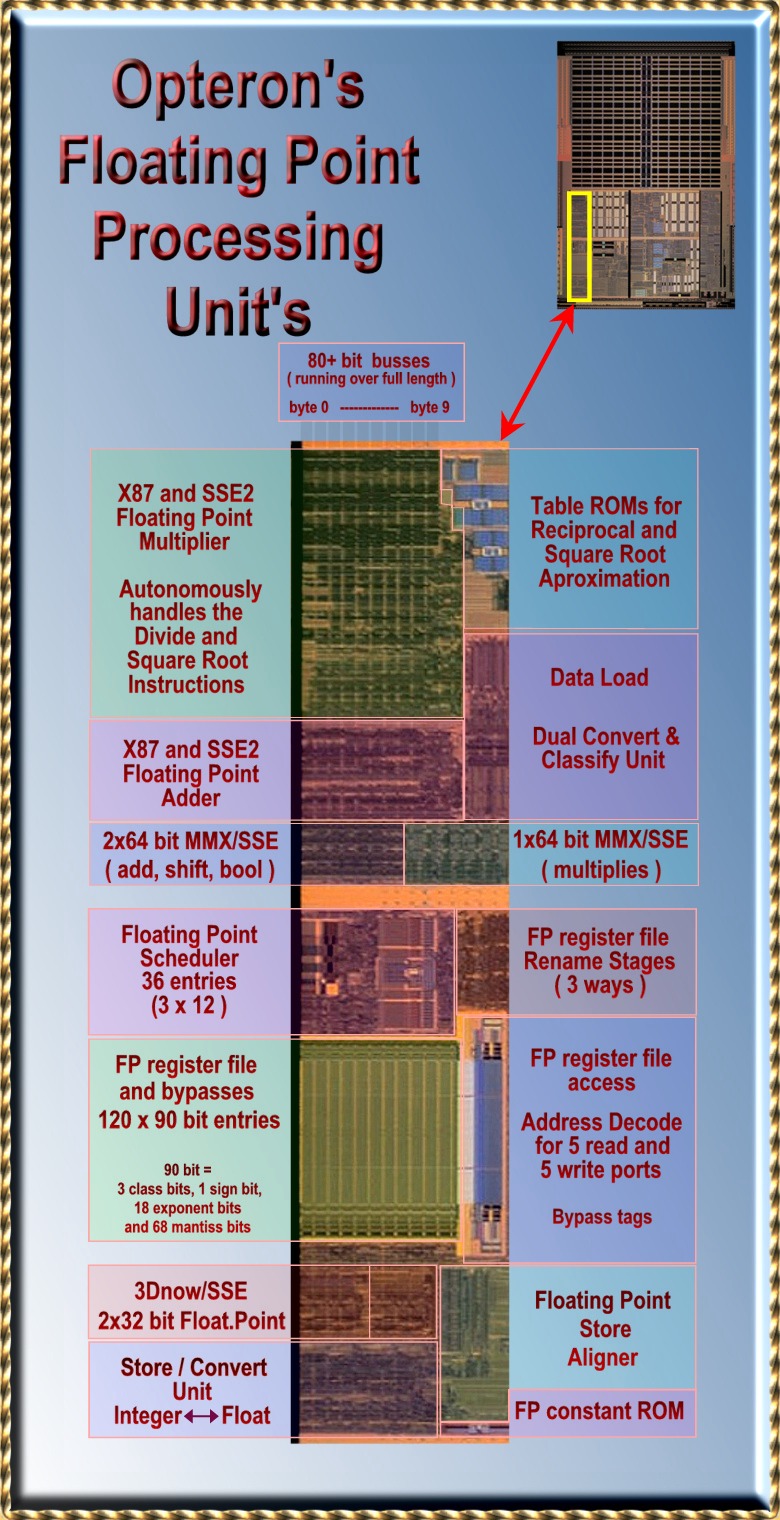




Bookmarks