-
Intel Larrabee Roadmap 48 cores in 2010
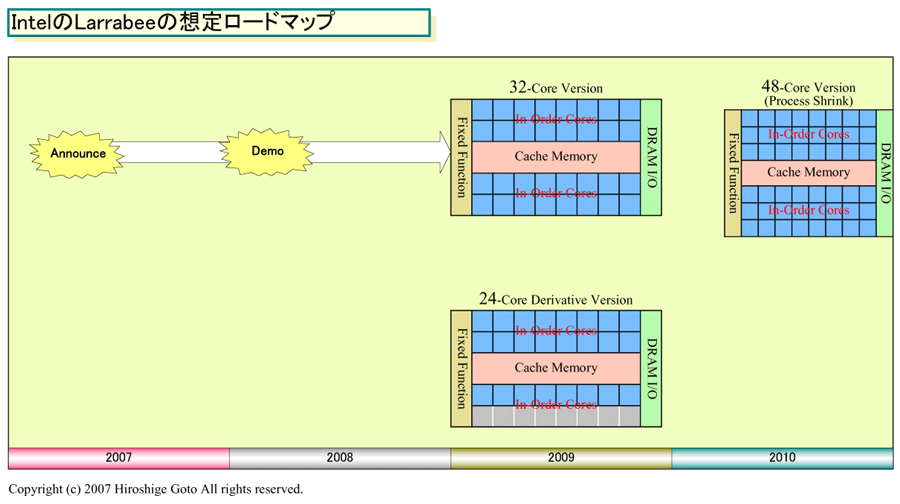
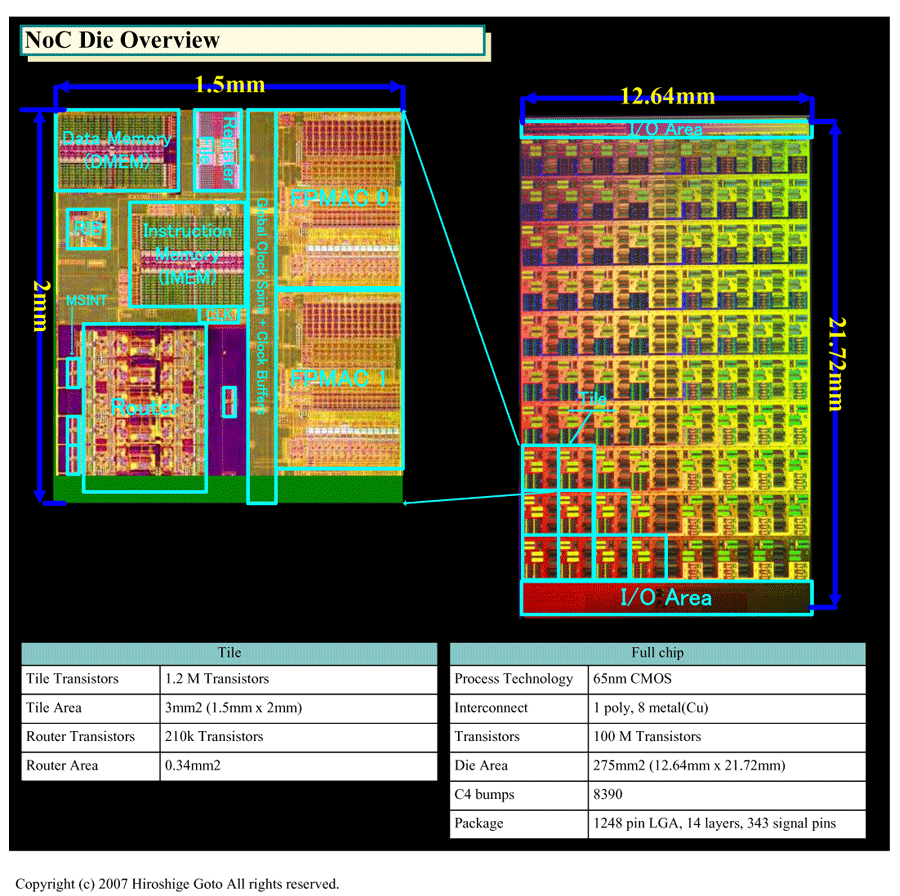


http://pc.watch.impress.co.jp/docs/2.../kaigai364.htm
The CPU architect team takes charge of development
Larrabee which was seen as discrete GPU for a long time really is not GPU. It is メニイコア CPU which is specialized in the stream computing which processes many data in parallel. Gelsinger expresses as follows.
"Larrabee is the high-speed steel kale parallel machine. We load very many cores, our メニイコア (Many-core) become the first product "
Larrabee which adhered to x86 instruction set architecture
The largest point of Larrabee IA (x86 system) expanded instruction set architecture, it is the point which is the high parallel processor. There differs from GPU and the other stream processor of individual instruction set architecture largely.
"The core of Larrabee is IA instruction set interchangeable. This thinks that it is very important feature. However, floating point order is expanded to instruction set. It is the instruction set expansion which is specialized because of high parallel workload. In addition, cash coherency is taken in the form which extends over the core (joint ownership) it has cash. This (キャッシ
コヒーレンシ) when of プログラマビリティ is thought, it is very important. In addition, special use unit and I/O are loaded.
Larrabee, never, GPGPU (general purpose GPU) is not the traditional graphic pipeline in the space. General-purpose processor, in other words, it is the processor which is directed to the use where IA プログラマビリティ becomes important. But, it can answer to the workload of specification, with the expansion of instruction set, "(Gelsinger)
Like GPU, it is not the product which reforms the graphic pipeline in for general-purpose road, the fact that the approach whose is widely used is taken is Larrabee. Because of that, IA (x86 system) the rear interchangeability to instruction set architecture is taken. Starting from the IA core which is general purpose CPU, to the micro architecture which faces to the stream type computing of floating point arithmetic it is the processor which is expanded.
Actually, also discrete GPU plan of the Intel graphic core team exists to Intel. This differs Larrabee completely architecture and mounting, you say that it is discrete edition of Intel graphics. As for graphic integrated chip set of the CSI generation, because it is easy to derive discrete GPU, as for this it is the natural flow. Intel was advancing this project from the time before, but as for the concrete product road map because it is not audible, there is also a possibility of going out.
GPU the parallel processor of the approach which differs
The performance of Larrabee with graphic processing is unknown. As for graphic processing because it approaches to the execution efficiency of シェーダプログラム steadily, as for the possibility architecture of Larrabee type becoming advantage it is high. But, like rasterizing like processing and filtering and the luster operation where the functional unit which is locked completely is more effective the processing whose semi- fixed unit is effective is mainly included in the graphic pipeline. When these are processed with all processors, wastefulness increases performance/electric power mainly.
Because of that, efficiency with graphics, depending upon Larrabee how much has GPU hard, changes. Circuit scale there is also a possibility of having private hard concerning small unit.
It is clear present Larrabee not to be something which was focused to graphics, to be the architecture which approached to non graphics rather.
==================================================
http://www.tgdaily.com/content/view/32447/113/
Intel aims to take the pain out of programming future multi-core processors
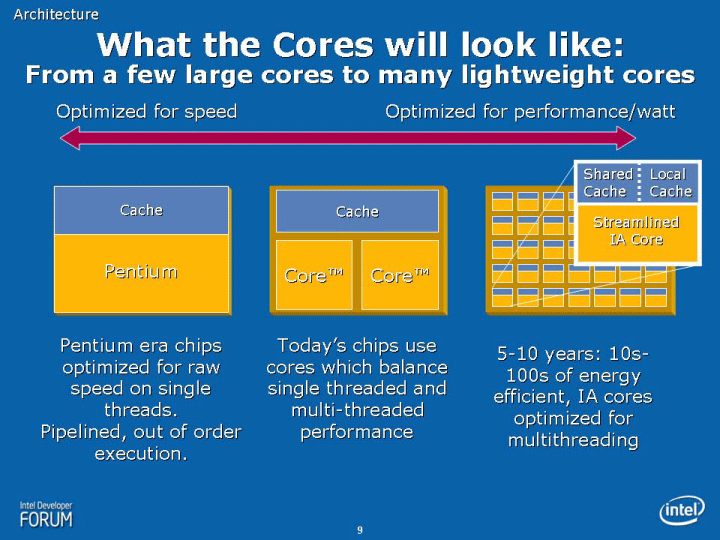
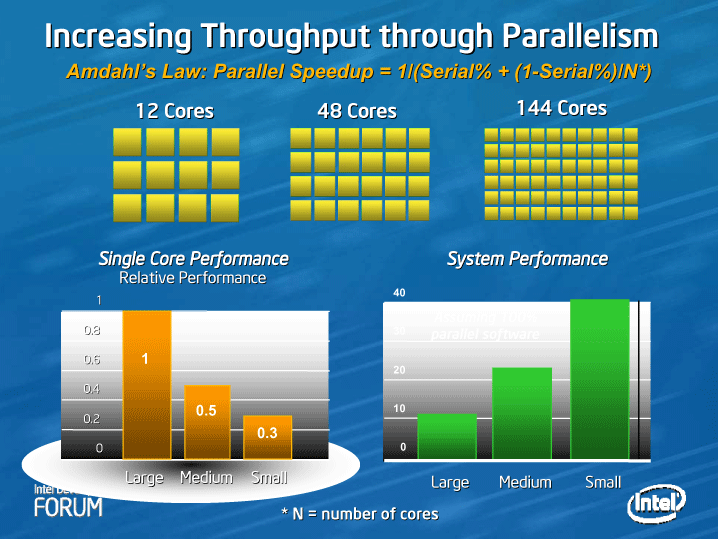
Santa Clara (CA) The switch from single-threaded to multi-threaded applications to take advantage of the capabilities of multi-core processors is taking much longer than initially expected. Now we see concepts of much more advanced multi-cores such as heterogeneous processors surfacing which may force developers to rethink how to program applications again. Intel, however, says that programming these new processors will require a minimal learning curve.
As promising as future microprocessors with perhaps dozens of cores sound, there appears to be huge challenge for developers to actually take advantage of the capabilities of these CPUs. Both AMD and Intel believe that we will be using highly integrated processors, combining traditional CPUs with graphics processors, general purpose graphics processors and other types of accelerators that may open up a whole new world of performance for the PC on your desk.
AMD recently told us that it will take several years for programmers to exploit those new features. While Fusion - a processor that combines a regular CPU and a graphics core - is expected to launch late in 2009 or early in 2010, users arent likely to see a functionality that is different from a processor and an attached integrated graphics chipset. AMD believes that it will take about two years or until 2011 when the acceleration features of a general purpose GPU will be exploited by software developers.

Intel told us today that the company will be taking an approach that will make it relatively easy for developers to take advantage of this next generation of processors. The company aims to hide the complexity of a heterogeneous processor and provide an IA-like look and feel to the environment. Accelerators that are integrated within the chip are treated as processor-functional units that can be addressed with ISA extensions and a runtime library. Intel compares this approach with the way how multimedia extensions (MMX) were integrated into Intels instruction set back in 1996.
As a result, Intel hopes that developers will be able to understand these new processors quickly and develop applications almost immediately. It is a very small learning curve, a representative told us today. We are talking about weeks, rather than years.
Nvidia, which is also intensifying its efforts in the massively parallel computing space, is pursuing a similar idea with its CUDA architecture, which allows developers to process certain applications - or portions of them - through a graphics card: Instead of requiring a whole new programming model, CUDA can be used by a C++ based model and a few extensions that help programmers to access the horsepower of an 8-series Geforce GPU.
Last edited by coffeetime; 06-13-2007 at 06:55 PM.
 Posting Permissions
Posting Permissions
- You may not post new threads
- You may not post replies
- You may not post attachments
- You may not edit your posts
-
Forum Rules





 Reply With Quote
Reply With Quote
Bookmarks