




what mbreslin said is absolutely correct.
Of course the downside is that this is a major time drain.
I am doing exactly this (all this week) to find the sweet spot of # of drives/stripe size/allocation size.
So many variables - you (and all of us) need time and patience to find that sweet spot.

 Reply With Quote
Reply With Quote





 i dont think ive done a full run in the last hundred or so...
i dont think ive done a full run in the last hundred or so...

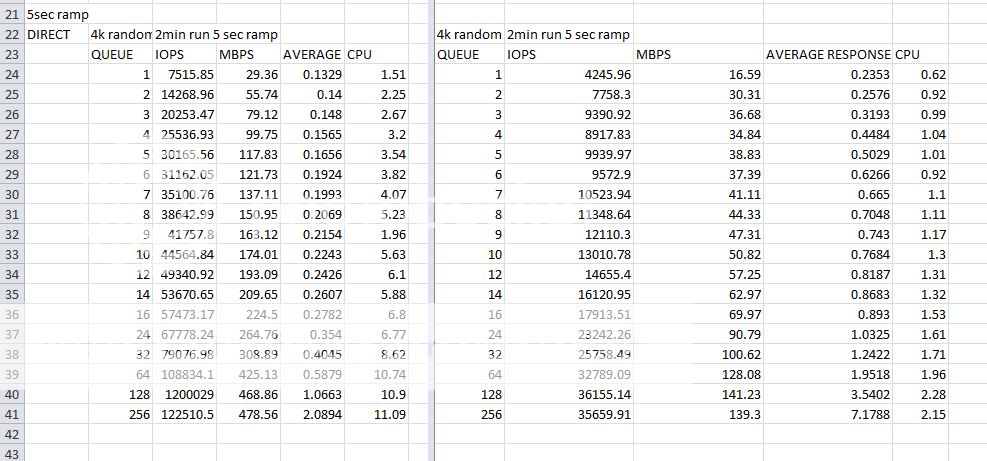

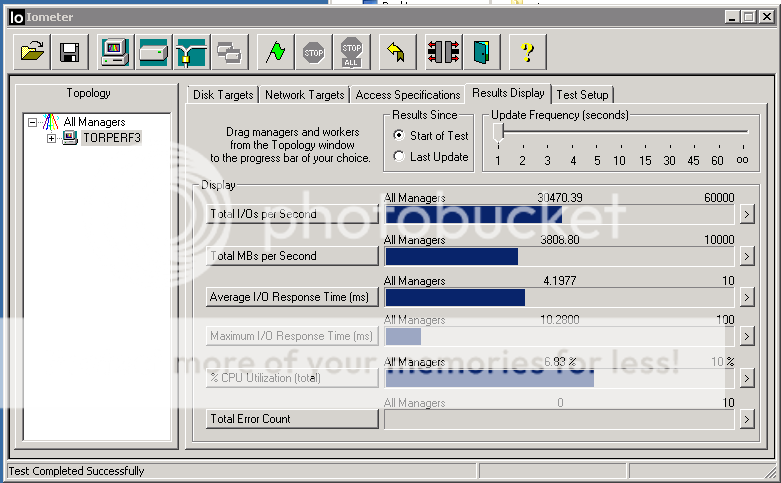
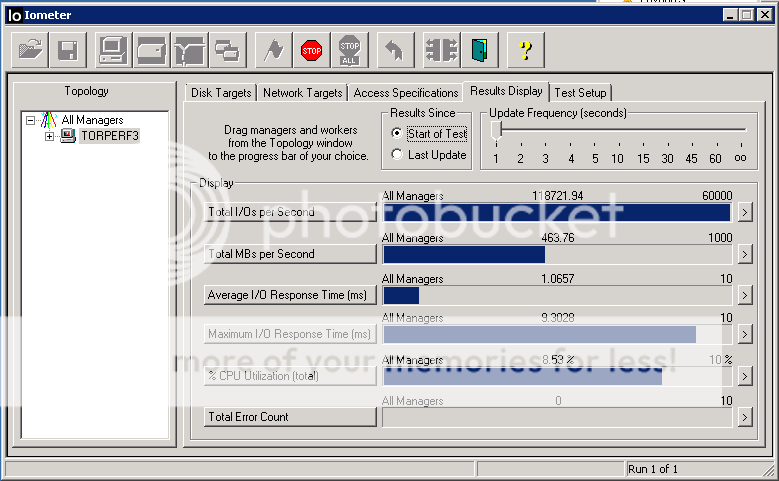


Bookmarks