




nicely saidOriginally Posted by ***Deimos***
 I want to put an end to the "dead horse beating".
I want to put an end to the "dead horse beating".
R600 vs Fermi
both: hot, new DX, late
diff: Fermi is faster, not broken, amazing DX11 features/performance for future games, good MSRP (markup another story).
fx vs Fermi
both: hot, new DX
diff: Fermi is faster, not broken, no questionable "optimization" (yet) and doesn't sound like turbine
GeForce vs Fermi
both: hot, new DX, foundation for new technology lineup.
Basically,
ALL new DX cards are always hotter. That's the trend. Get over it.
Even RV870 was gotter than RV770. Its not somehow a new issue only Fermi has.
Somehow, in the rosy glamourous faded memories, many people forget 9700pro was ridiculed for requiring extra power connector with ATI's classic Win2000 driver issues and at best performance on par with GF4. Ofcourse a year later, with issues fixed and DX9 launced, everybody was buying one.
Die shrink will be too late. 512 SP not important. Its like 5% difference.
There is 1, and only 1, critical "to-do".
DEVELOPERS.
If Fermi can get +20% in BattleForge, an "AMD game", image the performance if it was TWIMTBP!
Developer support is more critical than ever. All the consoles are DX9. There's little motivation to do "hard work" to make DX11 games.
It doesnt matter if its 480 SP or 512 SP, if nVidia isn't there to baby-hold and show 1-2-3 how to use it. Because if it never gets used, there's no benefit of having it.





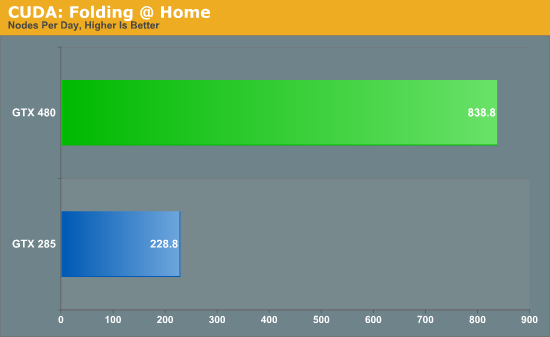

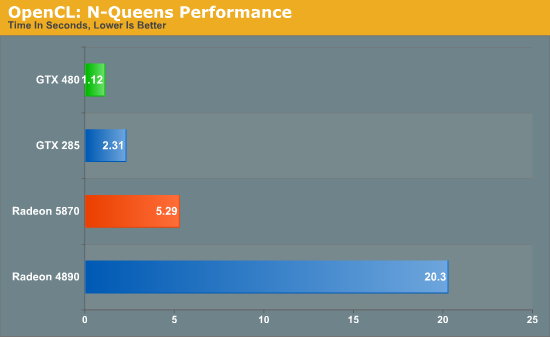
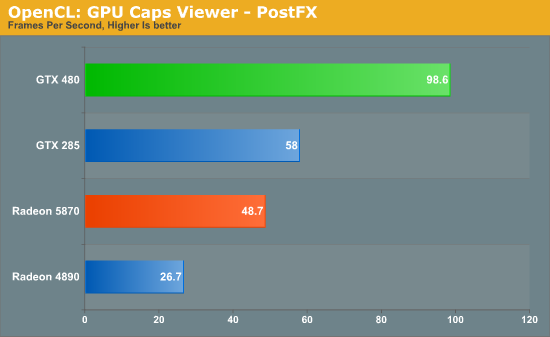
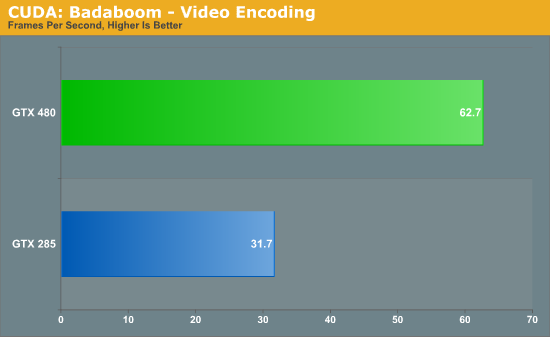









Bookmarks