




In the past I've allways favoured pi benchmark. Over the past years unfortunatly I haven't found the time (and space) I needed to really get going with it. Since last summer I've picked up my favorite past time activity again and started to bench with my new dual core cpu and cascade. However I didn't really liked calculating pi as I did before, mainly because the calculations were only using 50% of the resources available, and the other core was doing nothing at all
After playing around a bit with S-Pi my cascade sprung a small leak making it impossible to create a nice score. So it went out for maintenance. The leak is going to be fixed and an additional stage is going to be added, leaving me with some free time. Since that time quad cores have been released and 6 and 8 core cpu's are planned for later this year, early next year. Because I have some programming skilzz I decided to spend my time to see if there is a way to create a true multithreaded Pi benchmark application. Somewhere on the internet I found some nice algorithms I used in this app.
It took me some time, but finally I have something ready, though it is still in a beta phase. Here it is....
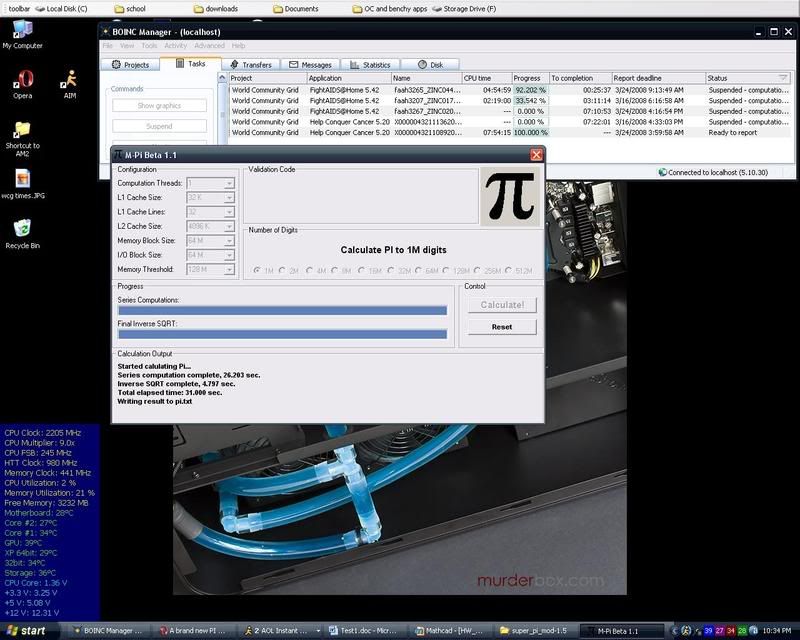
About the settings:
The algorithms are designed to optimize the calculations based on your system configuration. Therefore I've thrown in a few options to optimize the result of the calculation, giving you some more options to tweak the result.
The calulation thread are the number of threads used for the actual calulation. Besides this number of threads two more threads are created controlling the interface and the calculation, but those aren't doing a lot during the calculation.
The cache options are meant to optimeze L1 en L2 cache hits increasing the calculations performance. Setting them to low or high will have a negative effect on the benchmark result.
The block size options are fixed at 64M at the moment. Some work still has to be done in oder to get these options really going well. Like the cache options the blocksize options also influence the decisions for algorithms to be used only in a different part of the calculation
Memory Threshold is the maximum value for memory to be used for parts of the calculation. Going above this value means disk storage is going to be used for calculations. While this allows for calculating a huge number of digits for pi, you don't it to happing during the not so huge pi calculations.
Not available yet in this beta:
- Use of disk storage for the really large calculations, or systems with "only" 512MB of RAM
- Calculations optimized with block sizes.
- Validation of the calculated result. Is the number calculated really Pi?
- And also very important; the generation of the validation code.
The validation code will only be implemented in the final release
Feedback
I hope you all like this new program, but any feedback is welcome. At the moment I am still working on it and if you really like some extra feature let me know and I'll see what I can do. Also please report crashes in the program, instabilities or unexpected results.
I am hoping to see some nice screenshots now
Have fun!
Beta 1.3 is available, see a few posts below for the changes...



 Reply With Quote
Reply With Quote

























Bookmarks