

wplachy


wplachy
Had a bit of a play around with settings on this trying to find a reason why threads would stall or the video driver would fail and restart.
This evening I have been running the latest driver and adjusted to 7 threads having tried 8,6 and 5 previously on this 7950.
My logic was that 1,2,4 and 7 are all divisors of 28 CUs, 112 SIMD Engines found on this card.
This needs more work but for the first time in a while I have had no issues even while doing other things on this rig.
anyone else got hints or tips?

My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
I think I've read on the Einstein forums that the WUs are bandwidth / memory intensive and it doesn't take more than a couple concurrent WUs to saturate. IIRC when I was running a 7950 (Win7 x64 on a 4670K) there was minimal gain between 2 and 3, I never tried with higher multipliers. Can you post more details on what PCI-e settings you are running (I'm guessing PCI-e 2.0 @x16) and the results you were getting at each multi? The rig I have the 7950 in now is 980X @3.6GHz w/ 6GB triple channel 1600C7 and while our CPUs are a bit different I'm guessing they are close enough for general comparison. I'll fire up 4x later today and post back with results ... oh wait ... what are you running your GPU and VRAM at - can we do this at say 1100 GPU and 1250 VRAM? I'll give it a few hour before I switch over to see if you're around and we can agree on settings, I guess we should establish how many CPU threads we want to provide for each WU - I typically go with 1 to 1 ratio. Any other setting we can standardize on that you think might make a difference?
I just switched to 4 threads and 4 cores. I will run out the remaining wu's so that fresh ones are used for comparison
MB is msi x79a gd45 8d, ram is 2* 8gb trident so dual channel only, running at 989.4 (1978.8). cpu = e5 26xx @2.544. Card in a pci-e gen3 x16 slot
card currently set to 1150/1600 so I will adjust in time for the fresh wu's running. catalyst 13.12. 89% load at these settings
Let me get a few done though first so I can compare with current test.
What about starting side by side test in 24 hours ish?
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
Sounds good ... poppageek's been pushing me a bit on the statsOriginally Posted by OldChap

so I could do with boosting my numbers!
Do you know the limits of card etc?
I'm wondering if , once it is determined how many instances to run, we could try higher card mem speed then hi vs low rig mem speed
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
I know I have not tried OCing the VRAM - you were running good at 1600 vram which seems pretty high but if that's stable I think it is a high enough bump to see if a difference exists.
My ASIC's quality is bad (70.1%) but I *think* I've had it running up at 1250 stable but had to pump lots of V ... which turns into a power pig and that's just not where I'm at these days but I can push things around for the sake of experimenting ... so it might last a few weeks to dial it in precisely ... that's OK with me :-)
So we start at 1100GPU and 1250 VRAM to baseline any overall differences between our rigs and then can start moving GPU and VRAM separately to get to best config for Einstein quickly ... that's the plan right?
Not sure it would matter or by how much but any thoughts on bumping PCI clock as a third parameter?
<edit>For anyone watching we are testing with BRP5 (Perseus Arm) as that's the app you get the most points with on Einstein. The downside to this is that you have much less of a chance, statistically speaking, of discovering a binary pulsar as it is searching outwards from the galactic center (less stars) instead of inwards where there are many more stars in general.
Last edited by Snow Crash; 01-11-2014 at 11:26 AM.
Yep, start at 1100gpu and 1250 vram. we can look at going either way from there once we have a baseline. My pci clock is at 105 just now.... you think I should drop it for a while?
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
Maybe drop it for the baseline run and then you push PCI and I push VRAM we will be able to compare on each system and get to optimal configs quicker?
<gpu@1100, vram@1250, PCI@100>
<first set of four>avg. 12,670 seconds / 4 = 3167 seconds each.
<total avg after 8 complete ... 12700 / 4 = 3175 seconds each
In the morning (UTC -5) I will try bumping vram to 1500 - I figure if a 20% OC doesn't show much then it's not worth pushing to the edge.
<gpu@1100, vram@1500, PCI@100>
This only reduced runtime by about 1 minute per WU, well within normal variation between WUs
January 13
<gpu@ 900, vram@1250, PCI@100>
Hmmm avg 12500 / 4 = 3125
This is either WU variation or we've found an odd situation where the GPU / VRAM speeds are better in sync increases overall efficiency?
January 14
<CPU usage>I should have done this at the beginning - check to make sure we are running same CPU project, but I didn't and I think that is what accounts for the relatively minor discrepancies we are seeing.
I stepped all the way back and decided to see what happens to GPU utilization when I started freeing up more CPU resources
With 2 Test4Theory CPU project running: 1 Einstein runs at ~82%, 2WU ~92%, 3WU ~95%, 4WU ~95%, 5WU ~95%
---- so the biggest jump is from 1 to 2 WUs ... that's a no brainer, 2 to 3 eeks out a couple more percent but 4 doesn't look like it is doing anything for us, and once or twice I saw 5 WUs spike to 96% ... hardly an endorsement for increasing efficiency. I'm starting to wonder if the better overall runtimes we are seeing running a larger number of concurrent WUs is based largely on freeing CPU resources (my app_config is set to use 1 CPU per).
With CPU projects running on all cores except Einstein: 1WU ~50-60%, 2WU ~65-70%, 3WU ~89-91%, , 4WU ~92-93%, 5WU ~93-94%
Now this is more like the utilization/ scaling and we are use to seeing. As you can imagine the spikey nature of utilization at lower concurrency count is due to the GPU waiting for the CPU and hence if there are more CPU resources available the quicker that happens. As you run more concurrent WUs there is some leveling that happens as while the GPU is waiting for CPU resources it can process the GPU portions for a different WU.
So where is the balance between these two positions - no CPU projects or full CPU projects? Based on the information above the best utilization seems to be 95% in any situation.
With CPU projects running on all cores -1 except Einstein: 3WU ~92%, 4WU ~93%, 5WU ~94%
Looks like 3 is the winner in gains on this trial. I did continue experimenting with reducing CPU project reduction but after n-1 there was not much difference.
I'm going to run 5 concurrent for the next 12 hours to see what that gets for runtimes (CPU n-1, gpu@ 900, vram@1250, PCI@100)
January 15 - 5 concurrent WUs
<gpu@ 900, vram@1250, PCI@100>
avg 16500 / 5 = 3300 ... appears on my rig there is too much overhead going on with 5 and while GPU utilization was up a hair, overall efficiency was down. Keeping in mind this could still be normal WU execution variation as we are only talking about 3 minutes over the course of 4 hours.
I think there is enough to fill in a few more lines.
I'm going to switch to the Albert project (Einstein's test bed) which is running the same app ... I just like to point hop around :-)
That's an interesting runtime on the 2 concurrent ... if it holds up then I think while the points end up the same overall it is a bit more efficient as your system is not handling the overhead of handling as many context shifts.
January 16
running 2 concurrent at stock gets an avg of 3604.33
running 3 concurrent at stock gets an avg of 3478.83
Last edited by Snow Crash; 01-16-2014 at 03:41 AM.
at first glance your faster processor is probably better.
I guess it is not necessary for us to do these tests at the same time, only that we do the same type of tests during the sequence
I propose something like this where we each test using stock frequencies on a card and then go to a reasonable oc with each of both gpu and vram then trial a similar test on cpu and ram.
Last edited by OldChap; 01-18-2014 at 08:45 AM.
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
Here, after getting interrupted by a beta test at WCG, is a bit of an update:
This one I will try to add info to over time.
I have to agree that a whole lot depends on what else is running at the time. I noticed that my instance of MJ12 plays havoc with the numbers here so my numbers are taken overnight with one thread for each E@H instance, one for each WCG (fah) and one idle
I also found that re-starting boinc is best after each adjustment. I must see how it behaves when running MCM1 alongside
Last edited by OldChap; 01-18-2014 at 09:00 AM. Reason: add
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
what would the app_config have to be for me to run both gpus in my system the same? right now its putting 4 wu on 1, and 1 on the other??? thanks for any help
What cards do you have and how many or which type of WU is your target?
The following is for BPR5 WU (which get the best points) and will run 2 WU per card and reserve 1 cpu per WU
Code:<app_config> <app> <name>einsteinbinary_BRP5</name> <gpu_versions> <gpu_usage>0.5</gpu_usage> <cpu_usage>1.0</cpu_usage> </gpu_versions> </app> </app_config>
tried a few of the Gamma-ray pulsar search #3 v1.11 (FGRPopencl-ati) but these only get 660 points in 10,000 secs vs 3,333 in 7,500 secs on (BRP5-opencl-ati) when running in pairs
My Biggest Fear Is When I die, My Wife Sells All My Stuff For What I Told Her I Paid For It.79 SB threads and 32 IB Threads across 4 rigs 111 threads Crunching!!
More support for (BRP5-opencl-ati) being the best points at Einstein ...
ON the gravity wave app ... the new beta 1.08 (GWopencl-ati-Beta) much has faster runtimes than the previous version
http://einstein.phys.uwm.edu/forum_t...ap=true#130590
It looks like almost 3 per hour + 24 hours = 72 so at 390.83 ea = ~9K ppd.Done ~70 v1.07 (GWopencl-ati-Beta) tasks on my HD7770 without problem, in a little over 1200 secs each, GPU is running a slot at PCI-E 2.0 x8 speed at present, and on APP runtime 1348.5
Claggy
IU know this will be an apples to oranges comparison but my 7850 gets almost 60K ppd on the (BRP5-opencl-ati) ... nope a 7850 is not 6x faster than a 7770.
Last edited by Snow Crash; 04-16-2014 at 03:13 PM.
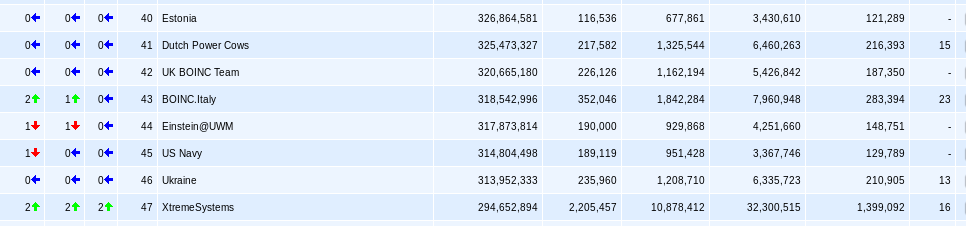
After months in the doldrums, we pass two in one dayWith a fair wind behind us, 40th should not take too long.

Of course if you only do 1.7M PPD there
I know, my bad. I'm aiming for 2M, but getting tasks verified takes forever

If you're aiming for the highest RAC then allow only BRP4G (2-3 weeks work available currently) or BRP5 (should have plenty of work).
The other tasks like GW S6Cas or FGRP give less PPD, involve more CPU and I had issues with them on AMD GPUs (errors, invalids).
Yes, never run both BRP4 and BRP5 at the same time ... ruins performance. I continue to find that BRP5 point better but there is a higher likelihood of finding a BRP in the "4" group (towards center of galaxy) than in the "5" (out in the perseus arm).
Well that's 40th done. Now let's give that familiar team at 34th a wake up call
 Posting Permissions
Posting Permissions



 Reply With Quote
Reply With Quote
















Bookmarks