

so when are you going to update the program to take advantage of the 1.4x speed up
good to hear you can fix the bug in it... now maybe the amd will give the intel some competiton....


so when are you going to update the program to take advantage of the 1.4x speed up
good to hear you can fix the bug in it... now maybe the amd will give the intel some competiton....
Its not overkill if it works.
I've been searching through the Windows docs and I can't find any option that'll do interleaved memory allocation. Some of the NUMA control functions "might" let me do an interleaved malloc() - I'm not sure yet.Originally Posted by skycrane

So for now, Linux is the only way to get that 1.4x speed up.At least until I find a way to do interleaving in Windows...
All the NUMA control features in Windows seem to require Vista or later. So when I use them, I'm probably gonna drop support for x86 (without SSE3).
Any processor old enough to not have SSE3 is not gonna be able to run Vista.So that's one less code-path I need to maintain... lol
Anyways, I'm gonna release a new patch for the program soon. It'll have the Bulldozer-compatible AVX binary, and my updated email address.
(My school finally terminated my northwestern.edu email since I graduated last year and I'm not a student there anymore.)
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)

Really? AVX makes that much of a difference?
Hmm....I wonder if programs like LINPACK would be able to pick up/use that difference?
Way I look at it - there's always going to be someone who knows more than I do, and there's A LOT of people who know less. (It isn't an ego thing, it's a reality thing, or so I've been told. I'm usually too busy doing my own thing to notice anyways...or care.)
I still wonder why don't you go with something like PGI or Pathscale or some of the more "generic" (less stupid/specific) compilers?
Haha...I got kicked off the school systems for a while because I was running the distributed.net client on their Sun SPARC servers. Then I was like "screw this" and ran it on my home systems instead cuz it was faster. When I went to re-activate my account, they're like "it looks like you're blocked. Hmmm...I dunno why." and I'm like "*shrug* I unno either..." LOL
Stupid class that actually needed access to the labs.
flow man:
du/dt + u dot del u = - del P / rho + v vector_Laplacian u
{\partial\mathbf{u}\over\partial t}+\mathbf{u}\cdot\nabla\mathbf{u} = -{\nabla P\over\rho} + \nu\nabla^2\mathbf{u}
The 1.4x is from the NUMA interleaved memory, not AVX.
Right now, AVX is only giving about 10% since the program is mostly integer and memory bound. I hope to change this situation in v0.7.x, but that's still a long way away.
I started with Visual Studio because it's easy to use and is user-friendly (integrated with GUI). Then I switched to the Intel Compiler since everyone says it compiles the fastest code and stays up to date with instruction sets.
I still use Visual Studio for most of the dev work. Only the release builds are compiled using ICC.
Switching compilers is actually a pretty big hassle. I have to rewrite all my batch scripts and re-tune a lot of the code if I want to get maximum performance.
EDIT:
Oh cool. I can compile FMA4 and XOP with VS 2010...
Too bad there's no way for me to run it.
Code:vmulpd ymm0, ymm0, ymm15 vfmaddpd ymm1, ymm1, ymm12, ymm0 vroundpd ymm5, ymm3, 0 vroundpd ymm14, ymm7, 0 vmulpd ymm0, ymm5, ymm4 vsubpd ymm3, ymm3, ymm5 vroundpd ymm2, ymm8, 0 vroundpd ymm11, ymm13, 0 vsubpd ymm8, ymm8, ymm2 vfrczpd ymm2, ymm1 vfmaddpd ymm1, ymm10, ymm3, ymm0 vmovapd ymm10, YMMWORD PTR [r15+32] vfmaddpd ymm15, ymm15, ymm12, ymm2 vfrczpd ymm2, ymm1 vsubpd ymm13, ymm13, ymm11 vfmaddpd ymm0, ymm4, ymm3, ymm2 vsubpd ymm7, ymm7, ymm14 vroundpd ymm6, ymm9, 0 vmovapd YMMWORD PTR _a2$2$[rbp], ymm0 vmulpd ymm0, ymm14, ymm8 vsubpd ymm9, ymm9, ymm6 vroundpd ymm1, ymm10, 0 vfmaddpd ymm1, ymm1, ymm7, ymm0 vmulpd ymm0, ymm6, ymm13 vfrczpd ymm2, ymm1
Last edited by poke349; 04-05-2011 at 12:48 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I thougth that VS was just the programming interface and that you still have to have the compilers separate from VS (or that it has to be like integrated/installed afterwards or something)?
I don't know. My prof used to use VS just to hit 'F5' to compile (or something like that) but otherwise, he used to use Compaq Visual Fortran, which became Intel Visual Fortran.
The very very very miniscule amount of programming that I've done, I've used gcc/g77 and did it using in cygwin.
flow man:
du/dt + u dot del u = - del P / rho + v vector_Laplacian u
{\partial\mathbf{u}\over\partial t}+\mathbf{u}\cdot\nabla\mathbf{u} = -{\nabla P\over\rho} + \nu\nabla^2\mathbf{u}
Visual Studio has it's own compiler. It's actually pretty decent. VS 2010 is actually competitive with the Intel Compiler for optimizing code.
Also, I just released v0.5.5.9180 (fix 2).
The AVX binary should work on Bulldozer. But of course I won't know for sure until someone tries it.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
is the vs2010 sp1 compiler faster in sse4.2 as well compared to the intel compiler? It would simplify my build script for open source emulators a lot.
I haven't used SSE4.2. It's mostly string-processing stuff - which isn't that useful for computation-heavy apps.
But for SSE4.1 and down, it is very very close. The Intel compiler is less than 1% faster than VS 2010 SP1 for y-cruncher.
At this point, it'll depend heavily on the type of code you're doing.
y-cruncher has a lot of very large blocks of branchless straight-line code. (often more than > 1000 instructions)
This is pretty typical of HPC apps.
Visual Studio has always sucked for this type of code.
The Intel Compiler has always been pretty good - if it's done right.
GCC seems to be competitive with the Intel Compiler - but it's hard to compare since it's Windows vs. Linux.
But now I'm tempted to think that VS2010 SP1 is much better at optimizing this type of code. Though I'm gonna need to run some benchmarks to see for sure.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
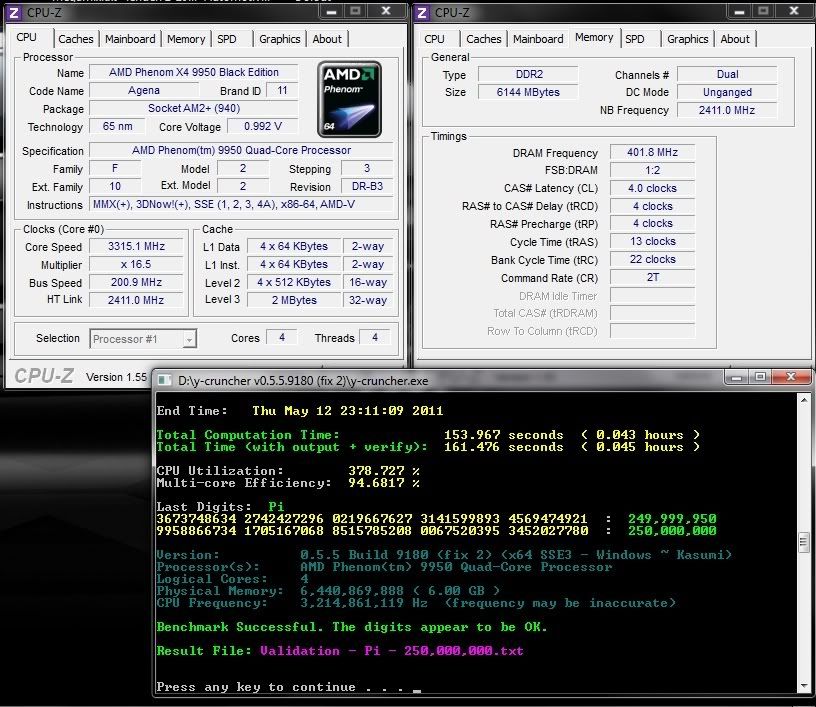
poke, I have a question regarding instructions that y-cruncher uses. I noticed that on Intel CPU's it uses SSE4.1, on AMD it uses SSE3, but as I see it in CPU-Z AMD has SSE4A. I don't know much about this stuff, but is there any use of the SSE4A?
________________
Main:
Phenom II x6 1090T BE|Crosshair IV Formula|Corsair 4x2GB DDR3|Sapphire HD5870|Adaptec 2405 + Hitachi Ultrastar 15k 450GB SAS, Toshiba MBD2147RC 146GB 10k SAS, Samsung F3 1TB, Seagate Barracuda Green 2TB 5900RPM, WD Black 2TB, Seagate Barracuda ST2000M001 2TB|Asus Xonar Essence ST + HD600|Corsair HX850|HPZR24w|Fractal Define XL Black|Windows 7 X64 Pro
Backup/Storage server:
HP Proliant ML350 G4|2 x Xeon "Nocona" 3GHz|4GB DDR1 ECC|Storage (SCSI): 3x10k 72GB + 10k 300GB + 15k 300GB + Ultrium460 tape drive|Storage (SATA): Adaptec 2810SA + 2 x WD Caviar 250GB RAID0 + Seagate 250GB|Windows Server 2008r2 Datacenter
Other:
HP Proliant DL380 G5|Xeon 5150|4GB FB DDR2 ECC|HP Smart Array P400-256MB cache|3x10k 146GB SAS in RAID 0 + 10k 146GB SAS|2x800W|ATi FireGL V7700|Samsung 226BW|Windows Server 2008r2 Enterprise
HP DL320 G5|Xeon 3150 2.13GHz|1GB DDR2 ECC|2x80GB RAID 0|Windows Server 2008r2 Standard
Laptop:
HP 8560w|i5-2540M|2x4GB DDR3|AMD FirePro M5950|Samsung 840 Pro 256GB|Windows 7 X64 Pro
SSE4a doesn't have anything that's useful for this application. Same applies to SSE4.2.
Also, I didn't have reliable access to an SSE4a machine until February this year.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
You do realize that you can kinda get gcc for Windows (via Cygwin).
I'm not sure how that all works out (whether it's emulated or whatnot--again not a programmer), but suffice it to say that for someone such as yourself, you might be able to make heads or tails of it and be able to at least run tests/benchmarks with it to be able to tell.
And for like some, they'd like recompile the kernel, the compiler itself, etc...so...it's a whole new giant can of worms.
But it IS available.
And I HAVE used it (a very insy tinsy tiny wee bit) with g77 (GNU Fortran 77 compiler), nothing like what you're doing. (Not even remotely CLOSE to it).
flow man:
du/dt + u dot del u = - del P / rho + v vector_Laplacian u
{\partial\mathbf{u}\over\partial t}+\mathbf{u}\cdot\nabla\mathbf{u} = -{\nabla P\over\rho} + \nu\nabla^2\mathbf{u}
I used cygwin GCC and Dev-C++ way back in my late high school and early undergraduate days. Then I "discovered" Visual Studio and found it a lot easier to use.
I've been too lazy to benchmark cygwin GCC now. I remember setting up the environment was a pain in the @$$. And then having to hook it up to Dev-C++ to override its archaic version of GCC.
Visual Studio was just double-click setup.exe and it's all ready - GUI and everything. Beats the hell outta all the Linux solutions...
I think my productivity went up like 3-fold when I switched from cygwin GCC to Visual Studio 2005.
The biggest part was the integrated debugger that would jump directly to the line in the source code that crashed - even with optimizations enabled.
It's a huge time-saver since it eliminates a lot of the guess work. There's a way to setup something like this in Linux, but I hear it's nightmare to setup unless you're experienced.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
Thought I'd give this thread a little bump - since it fell off the first page.
I've been busy as hell this school year, so I haven't been able to make too many improvements.
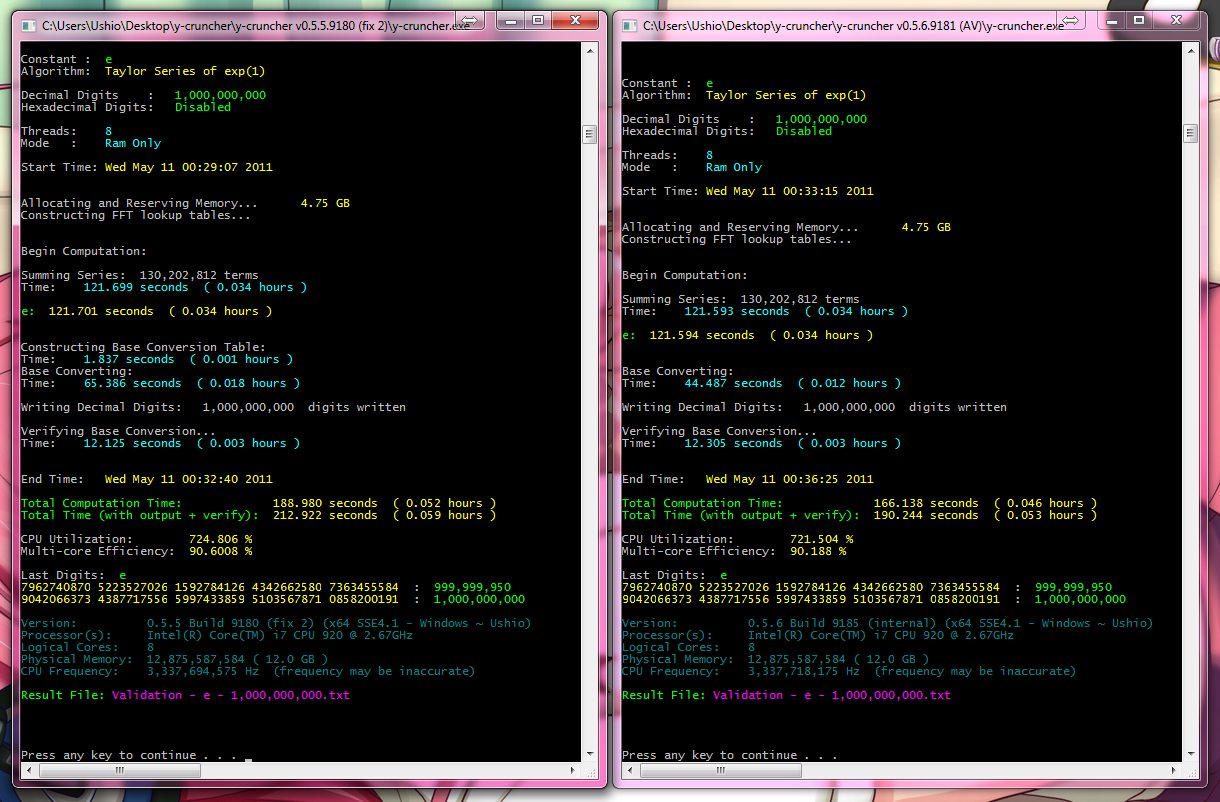
I have a slightly faster base conversion code. But it's ram only for now, I haven't extended it to swap yet.
Current Conversion Code (left): 1.837 + 65.386 seconds
New Conversion Code (right): 44.487 seconds
This new base conversion code won't be enabled until v0.6.x.
I've been working a completely new bignum interface. It's better, faster, more flexible, and more future-proof than the one y-cruncher currently uses.But it's also largely incompatible with the existing one.
This new base conversion is written using the new interface. For that screenshot above, I had to compile both the old and new interfaces together and then "hack" the new base conversion into the old code.
It works, but it's ugly and I don't think it's "stable" enough for production. It's gonna take a while to migrate y-cruncher to the new interface.
Sometime over the next year, I'll probably be releasing a Dynamic Link Library the exposes some of the low-level functions use by y-cruncher.
It'll be for Windows first, but I'll support Linux later.
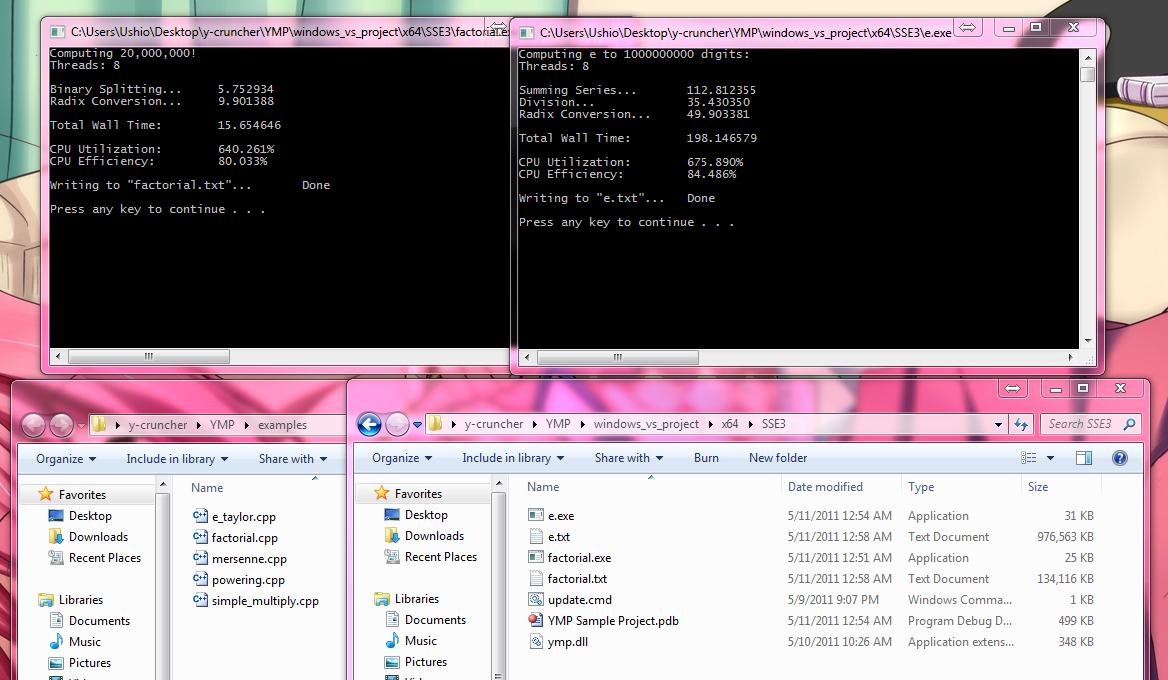
Here's a couple of tiny sample programs. Both examples are under 200 lines and use OpenMP and "ymp.dll". YMP is the name I've given to the library.
Sometime before I release the library itself, I'll be releasing the interface/documentation as well a large number of sample programs (including these).
If anyone's looking for a factorial benchmark...(20,000,000! is 137 million digits long!!!)
The other example computes e to a billion digits. It's not optimized at all - yet is almost as fast as y-cruncher.
Once I release the library, I'll be curious to see how people (if any) will use it.
Unless someone beats me to it, it'll probably be the first public bignum library to have multi-threading.
Last edited by poke349; 05-10-2011 at 10:53 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I tried this today and it seems to run 2c cooler than Prime95 26.6 but I do see that my VID under RealTemp is going from 1.3811 to 1.4111v basically its asking more juice!
For overclock stability test how many runs under stress test would you consider as 24/7 stable for gaming/movies/internet ?
Last edited by Demo; 05-12-2011 at 01:54 AM.
A test with an old unpopular CPU
It would depend on how stable you want. I typically run a combination of y-cruncher/prime95/Linpack for several hours, and then pull the frequency down by about 5 - 10%.
But that's just me. I do a lot of compiling work, so I can't afford any instability at the wrong times.
Neat.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
This any good? Ran at 4500mhz...
crunched.JPG
2600k 4.7-5.2 ghz /Megahalem Push/Pull
Gskill Ripjaws X PC1600 Cas 7 4x2gb
MSI P67A-GD65
MSI 560ti Twin Frozr 935/2100
Crucial C300 128gb/ 2 640GB WDAAK Raid Zero ViewSonic 24"
Antec 1200/Corsair 750 TX PSU / Win7 64bit
XS went down on Sunday or so... then I got tied down with other things.
I'll try to update the lists tomorrow.
btw, for any software devs interested in very large multi-precision arithmetic...
I've launched the website for the YMP library. Though it's still gonna be a while before it's ready for release.
http://www.numberworld.org/ympfl/
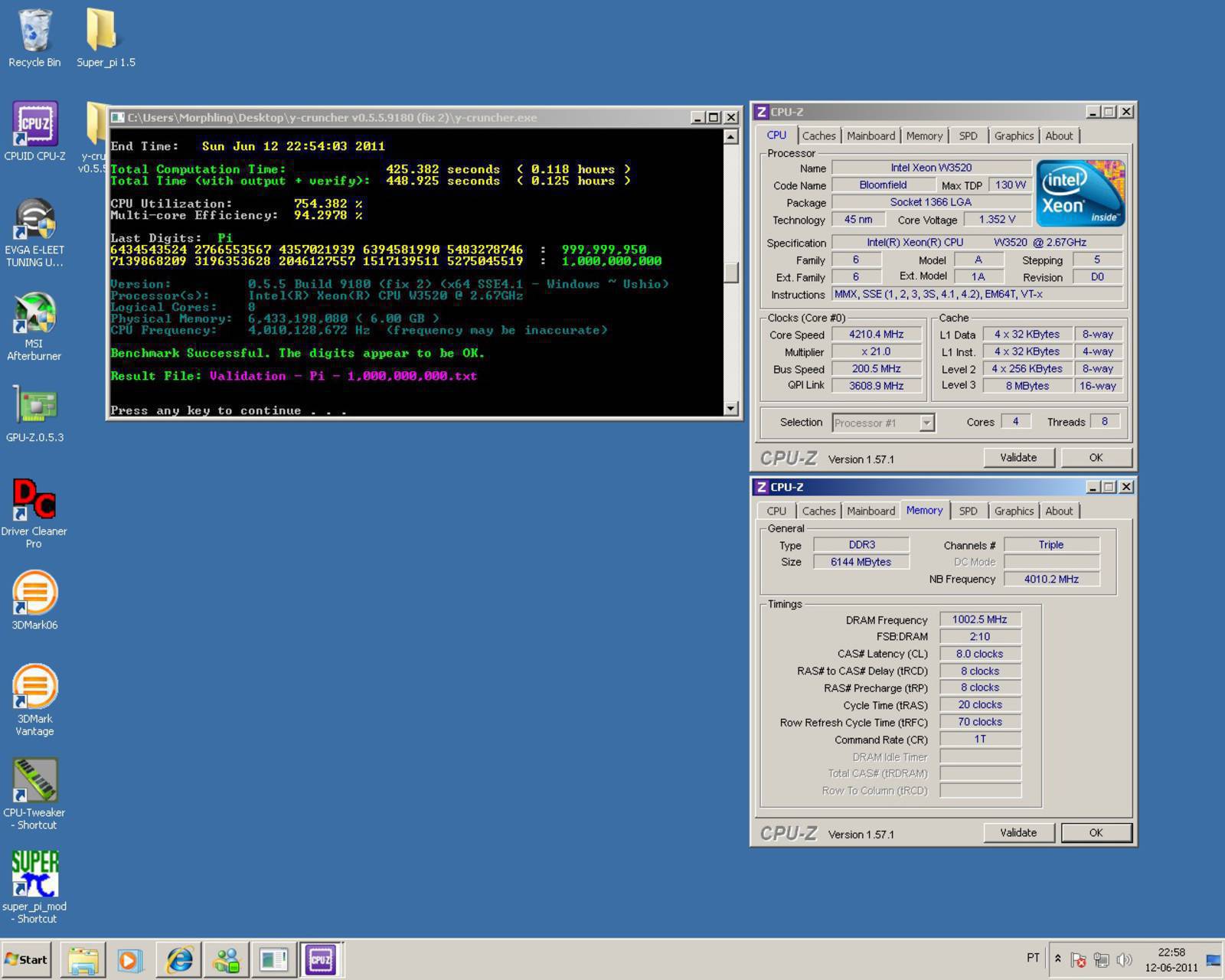
And here's another screenshot of the library.
This is computing Pi to 100 million digits using the same (slow) algorithm that SuperPi uses.
The source code for this is on that webpage (along with other examples), but you won't be able to compile it without the YMP library itself.

Last edited by poke349; 05-17-2011 at 11:02 PM. Reason: typo
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
i love big numbers! i'll be shooting you an email later in the hopes i get to play with the library! I can see multi-prime getting a bump....
Try my multi-threaded prime benchmark!
If you like it and want to see more - bitcoin me!!
1MrPonziaM4QT2S7SdPEKQH88BGa4LRHJU
1HaxXoRZhMLxMJwJ52VfAqanSuLuh8CCki
1ZomGoxrBqyVdBvHwPLEERsGGQAtc3jHp
1L33thAxKo1GqRWRYP5ZCK4EjTMUTHFsc8
Got your email. I'll respond properly tomorrow.
I was at ACEN (Anime Central) the whole weekend...
So my sleep schedule is completely #$%^ed up right now...
Lesson: Do not drive 85mph on Interstate 57 with a 30mph crosswind when you're not fully awake...
(I AM alive btw...)
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
i was reading through some of the documentation you have for you library and am i correct when i see that you have not implemented the modulo function?
Try my multi-threaded prime benchmark!
If you like it and want to see more - bitcoin me!!
1MrPonziaM4QT2S7SdPEKQH88BGa4LRHJU
1HaxXoRZhMLxMJwJ52VfAqanSuLuh8CCki
1ZomGoxrBqyVdBvHwPLEERsGGQAtc3jHp
1L33thAxKo1GqRWRYP5ZCK4EjTMUTHFsc8
Integer Modulus has been implemented, but it's not very well optimized.
There's two versions of it:
Modulus by a small integer (< 2^32):
This one is very slow (several times slower than GMP). That's because y-cruncher doesn't need this function at so there's no efficient implementation of it.
But for completeness, I had to implement it even if it's slow.
Modulus by a large integer (no size restriction):
This one is fast for large operands. (both operands > 1000 digits)
But there are some cases where it's horrifically slow compared to other libraries:
- When the operands are very small. (< 100 digits)
- When the dividend it much longer than divider.
y-cruncher doesn't use integer division (yet), so this function hasn't been properly optimized.
When I say "fast" or "slow", I mean fast/slow compared to other libraries. Larger operands will almost always be slower (in run-time) than small operands.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I've opened the documentation (for the YMP library) to the public.
It's here:
http://www.numberworld.org/ympfl/doc...n/general.html
I've also released the source code for the rest of the sample programs:
http://www.numberworld.org/ympfl/#Samples
You still won't be able to compile them since I haven't released the library yet. But it's something to look at for the curious.
The "pi_chudnovsky.c" example beats gmp-chudnovsky 4-to-1 on a Core i7. It's almost as fast as y-cruncher and it isn't even optimized.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
Here is my own rig:
Not so much, but it was just to participate
Cool, I'll update this in a bit.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
 Posting Permissions
Posting Permissions






 Reply With Quote
Reply With Quote




Bookmarks