

ya, he has me beat by about 100 seconds too. guess i need to work on my code...Originally Posted by bonis62

can't wait to see your new versions!


ya, he has me beat by about 100 seconds too. guess i need to work on my code...
can't wait to see your new versions!
Try my multi-threaded prime benchmark!
If you like it and want to see more - bitcoin me!!
1MrPonziaM4QT2S7SdPEKQH88BGa4LRHJU
1HaxXoRZhMLxMJwJ52VfAqanSuLuh8CCki
1ZomGoxrBqyVdBvHwPLEERsGGQAtc3jHp
1L33thAxKo1GqRWRYP5ZCK4EjTMUTHFsc8
To me.... this smells like a compliment
I recompiled it for x86 and got 17 seconds. So as expected, x64 is a bit faster.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
Indeed,
the difference is small, (bit)
i often wonder whether it is worth making two versions (64 / 32)
for this applications type ,
since the difference is minimal...
As of our current implementations, the difference is small.
But a more optimized version that stays in cache and uses hard-coded loop-unrolling will benefit a lot from the x64 registers.
x64 also lets you go over 2GB of ram.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
Here's what the N270 in my EEE 1000HE does (win 7 - completely stock).
--Matt
My Rig :
Core i5 4570S - ASUS Z87I-DELUXE - 16GB Mushkin Blackline DDR3-2400 - 256GB Plextor M5 Pro Xtreme

I may not set any world records, but at least I'm on the board. Was a bit weird having 16 threads spawned for 12 physical cores.
2x AMD Opteron 2427 @ 2.2GHz
8GB ECC/Reg DDR2-800
Windows Vista SP2 x64
Awaiting the new swap mode.
Particle's First Rule of Online Technical Discussion:
As a thread about any computer related subject has its length approach infinity, the likelihood and inevitability of a poorly constructed AMD vs. Intel fight also exponentially increases.
Likewise, the frequency of a car pseudoanalogy to explain a technical concept increases with thread length. This will make many people chuckle, as computer people are rarely knowledgeable about vehicular mechanics.
When confronted with a post that is contrary to what a poster likes, believes, or most often wants to be correct, the poster will pick out only minor details that are largely irrelevant in an attempt to shut out the conflicting idea. The core of the post will be left alone since it isn't easy to contradict what the person is actually saying.
Rule 2A:
When a poster cannot properly refute a post they do not like (as described above), the poster will most likely invent fictitious counter-points and/or begin to attack the other's credibility in feeble ways that are dramatic but irrelevant. Do not underestimate this tactic, as in the online world this will sway many observers. Do not forget: Correctness is decided only by what is said last, the most loudly, or with greatest repetition.
Rule 3:
When it comes to computer news, 70% of Internet rumors are outright fabricated, 20% are inaccurate enough to simply be discarded, and about 10% are based in reality. Grains of salt--become familiar with them.
Remember: When debating online, everyone else is ALWAYS wrong if they do not agree with you!
Random Tip o' the Whatever
You just can't win. If your product offers feature A instead of B, people will moan how A is stupid and it didn't offer B. If your product offers B instead of A, they'll likewise complain and rant about how anyone's retarded cousin could figure out A is what the market wants.
Nice, another Atom to add to the list.
Nice. That's the first 12-core that I can add to the list.
If you haven't taken a look yet:
I've added 3 entries of the new swap mode to the table.
Each of them showing a computation that is MUCH too large than would fit in ram.
And if it isn't obvious enough already, disk bandwidth is pretty much the only thing that matters.
Even on my workstation with 4 x 1TB (~400 - 500 MB/s), it is still highly bottlenecked by disk.
So if you have those velociraptors ready by then...
Also, if bandwidth doesn't scale linearly in raid 0, than you'll wanna undo the raid. The program is able to manage multiple HDs separately and get perfect linear scaling.
If it goes well enough upon release, I might start a new thread for it:
"Pi-based Hard Drive Benchmark for the EXTREMELY Patient"
EDIT:
About the 16 threads.
There's a number of algorithms that simply don't work with non-powers of two, so to get around it, I simply round up and let the scheduler take care of it.
Last edited by poke349; 02-09-2010 at 02:12 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
Is it more latency sensitive or bandwidth sensitive? The hard drives I've got aren't velociraptors--they're Fujitsu MBA3147RC 147GB 15K SAS drives. They do about 115MB/s each but offer an impressive 5.2ms (in real life) average random access time. I'll have eight of them at the end of the week. Would it be possible to help you test a beta?
As a thread about any computer related subject has its length approach infinity, the likelihood and inevitability of a poorly constructed AMD vs. Intel fight also exponentially increases.
Likewise, the frequency of a car pseudoanalogy to explain a technical concept increases with thread length. This will make many people chuckle, as computer people are rarely knowledgeable about vehicular mechanics.
When confronted with a post that is contrary to what a poster likes, believes, or most often wants to be correct, the poster will pick out only minor details that are largely irrelevant in an attempt to shut out the conflicting idea. The core of the post will be left alone since it isn't easy to contradict what the person is actually saying.
When a poster cannot properly refute a post they do not like (as described above), the poster will most likely invent fictitious counter-points and/or begin to attack the other's credibility in feeble ways that are dramatic but irrelevant. Do not underestimate this tactic, as in the online world this will sway many observers. Do not forget: Correctness is decided only by what is said last, the most loudly, or with greatest repetition.
When it comes to computer news, 70% of Internet rumors are outright fabricated, 20% are inaccurate enough to simply be discarded, and about 10% are based in reality. Grains of salt--become familiar with them.
Remember: When debating online, everyone else is ALWAYS wrong if they do not agree with you!
Random Tip o' the Whatever
You just can't win. If your product offers feature A instead of B, people will moan how A is stupid and it didn't offer B. If your product offers B instead of A, they'll likewise complain and rant about how anyone's retarded cousin could figure out A is what the market wants.
Bandwidth sensitive. I've pretty much optimized out all the extremely non-sequential stuff...
With 8GB of ram, latency isn't gonna matter until you push above 150 - 300 billion digits.
(With 12GB of ram, I start getting latency issues at about 300 - 600 billion digits.
On my workstation with 64GB, 4TB of disk space it isn't enough for me reach the sizes that are large enough to hit latency slowdowns...)
EDIT:
It scales quadratically. Doubling your memory will quadruple this limit...
Should someone be crazy enough to push higher, the program may automatically do an algorithm switch that trades latency for bandwidth. (So less sensitive to latency, but uses more bandwidth.)
So it's likely that you'll never feel the latency unless you override the buffering settings to something that's completely messed up... (which the program lets you do)
Which at those sizes... I doubt anyone is gonna want to tie down their machines for too long.
(I would estimate a 100 billion digit computation to take at least 100 hours with a single Core i7 and 250 MB/s disk bandwidth.)
So for everyone else, this isn't gonna be a test for SSDs. With the sheer amount of writes it will do, it'll probably kill an SSD with a couple of runs...
If everything goes well... I should have a working beta ready in less than 10 days.
Last edited by poke349; 02-09-2010 at 03:12 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I've added some new details on the new version:
http://www.numberworld.org/y-crunche...n_history.html
And with that,
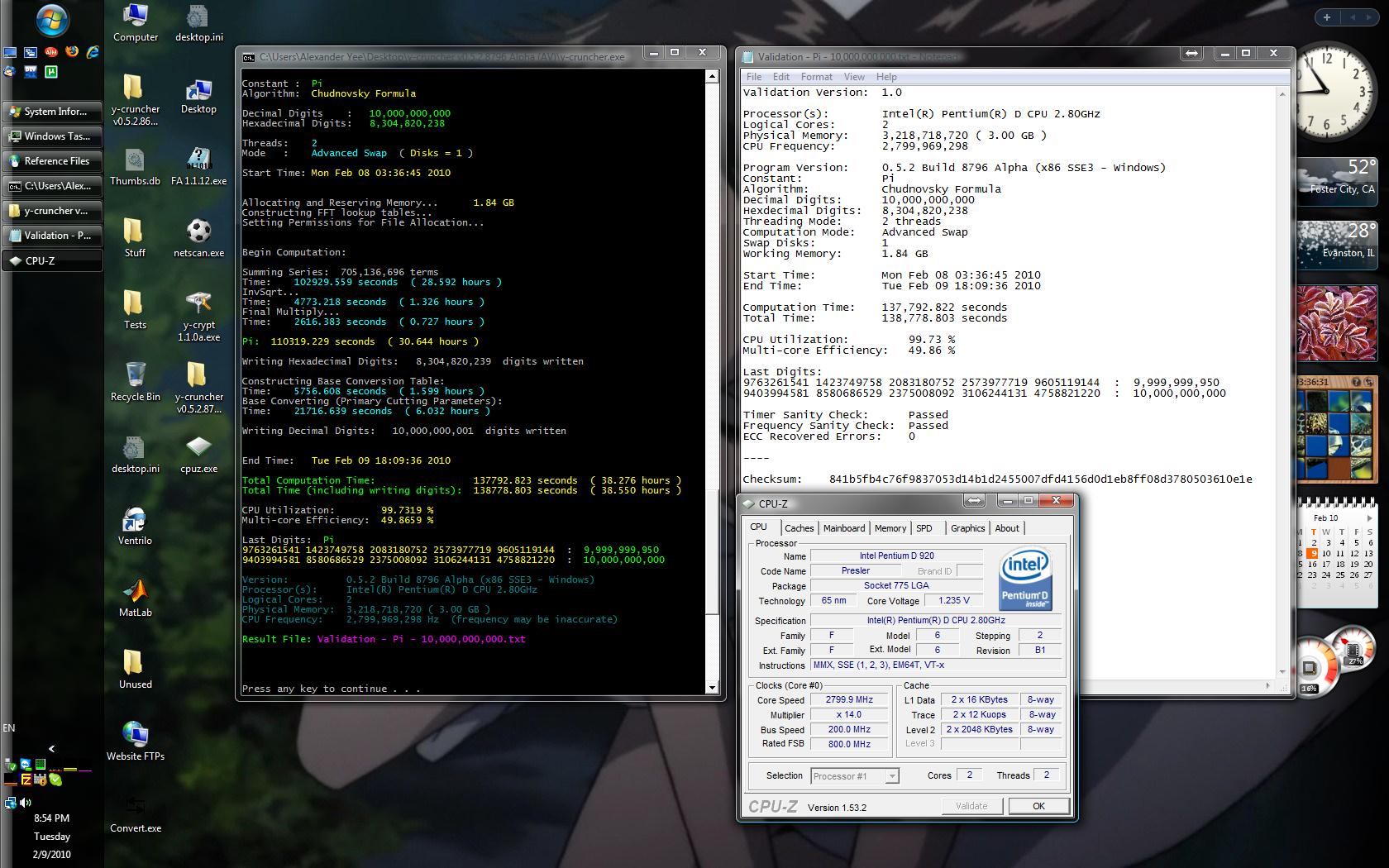
Here's the first two fully validated Advanced Swap computations with v0.5.2: (click to enlarge)
10 billion digits of Pi on my File Server - Pentium D @ 2.8 GHz + 3 GB DDR2 + 160 GB WD
x86 SSE3 - memory limit set to 1.84 GB.
10 billion digits of Pi on my Laptop - Core i7 720QM @ 1.6 GHz (stock) + 6 GB DDR3 + 500 GB Seagate
x64 SSE4.1 ~ Ushio - memory limit set to 3.00 GB.
Only the old benchmark mode will be able to verify if the digits are correct. (I obviously can't cache the last few digits of every computation size... lol)
For all other computations, (including these swap computations), the digits that it prints out will have to match the accepted values in order to complete the validation.
(the accepted values can be easily found online)
These two 10 billion digit computations took quite a long time (21 and 38 hours).
But that's because neither of the machines were "Xtreme" in any way.
In particular, my laptop's 500 HD is almost full so it only sustained 50 MB/s bandwidth.
I would expect that any "real" system (say a desktop C2Q/Ci7/PII X4) with a decent SATA II 7200 RPM drive will make 10 billion digits an "overnight job", or a "start in the morning, done before getting back from work" job...
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I want to compile my code in 64 bit,
i want to know what compiler you use for 64-bit
ty
http://www.xstreme.it/primes64.zip
my first attempt...
Last edited by bonis62; 02-10-2010 at 07:17 AM.
I use Visual Studio for general coding and compiling because it compiles very quickly.
But all final versions that use SSE are compiled using the Intel Compiler. It optimizes better than Visual Studio.
Both support x64.
Now you can try scaling up the size to more than 4GB of ram.
Though you won't know that you're bug-free until you test sizes that are large enough to overflow all 32-bit indexing in your program.
Which is where a lot of ram becomes useful... An array of 32-bit integers won't overflow a 32-bit index until it's larger than 16GB. And for 64-bit double, you need 32GB of ram...
But that's just supersizing... way more than what's needed for most applications.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
T Y V M
the FLOAT instead of DOUBLE saves bits and gains efficiency,
but i do not know if YOUR APP can work with FLOAT...
Just a MS Windows developer... My Web Page
I'm already pushing "double" to its limit of precision.
"float" has less than half the precision of "double" so that would require more than 4x the work.
Actually, because of the way the algorithm works, using type "float" would require MUCH more than 4x the work. It would actually fail above a certain (small) size.
The run-time complexity is this:
where "n" is the # of digits.
and "w" is the # of bits of precision in the floating-point.
When the denominator goes to zero, the run-time (and memory) blows up to infinity - in other words, the algorithm fails.
This is the reason why I can't use GPU.
If there was a 128-bit floating-point type that was supported by hardware, the program would actually be MUCH faster.
EDIT: That complexity is just a reasonable approximation to the true complexity.
The true complexity (ignoring round-off error), has special functions in it... so it's unreadable to normal people. (even myself)
Last edited by poke349; 02-10-2010 at 01:08 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
yeah
if
n=100.5
w=64.0
o= n/(w-Log(n))Log(n/(w-Log(n))) = 1.6922085689143893
it's your formula ?
but if you make this :
o= n/(w-Log(n))Log(n/(w-Log(n))) = 1.6922085689143893
o2= sqrt(o) = 1.3008491722388069
you have a large control predictor...
this is only my theory to bypass error
read this :
http://en.wikipedia.org/wiki/Floating_point
Last edited by bonis62; 02-10-2010 at 03:05 PM.
Just a MS Windows developer... My Web Page
It's just a Big-O... I didn't put any of the constants in there.
Basically:
With "double", w = 53. The algorithm becomes impractical when n goes above a billion. The asymptote is reached when n reaches ~25 trillion digits. (give or take a factor of 10 or so...)
With "float", w = 24. The algorithm becomes becomes impractical at just a few thousand digits. The asymptote is reached when n goes to a mere 60,000 digits... (again, give or take a factor of 10 or so...)
This is just one of several major algorithms in the program.
The program doesn't rely on it solely. So 25 trillion digits isn't the limit of the program.
EDIT:
Basically, when "w" is much larger than "log(n)", the complexity is roughly O(n log(n)). That's where the algorithm rules since it's quasi-linear.
So as long as you stay in that range, the algorithm remains efficient.
But as you push higher and higher, the "log(n)" starts creeping up. Eventually, it becomes inefficient. Then impractical...
And when n is large enough such that w = log(n), the algorithm fails completely.
This algorithm is called FFT multiplication.
Virtually all fast pi-programs use it, SuperPi, PiFast, QuickPi, etc...
All implementations of it stay in the "efficient" sizes where "log(n)" is much smaller than "w".
Last edited by poke349; 02-10-2010 at 03:46 PM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
last question
with the binary splitting method
"the impractical" resolves anything ?
http://numbers.computation.free.fr/C.../programs.html
Just a MS Windows developer... My Web Page
I don't think I understand what you mean...
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
see this
http://numbers.computation.free.fr/C...splitting.html
and this
http://algolist.ru/download.php?path...rc.zip&pspdf=1
is useful ?
Last edited by bonis62; 02-11-2010 at 05:50 AM.
Just a MS Windows developer... My Web Page
And your point?
EDIT:
If you're wondering is any of that is gonna help. I've already been using most of those algorithms since the very beginning.
Last edited by poke349; 02-11-2010 at 06:31 AM.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
I really wanted to know your point of view....
I am new to this type of algorithm,
i are documented on this subject,
i thought that theory to solve the problem of zero value,
with a NAN routine,
if the data is zero, replace with NaN,
but if you say that is impossible,
then it is just impossible
Just a MS Windows developer... My Web Page
k, sorry.
Now I'm REALLY confused.
I never mentioned anything about zero or NaN.
I only mentioned that it was impossible to use "float" to any degree of efficiency. (impossible is kinda strong of a word, I'll just say "extremely difficult")
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
you says
When the denominator goes to zero, the run-time (and memory) blows up to infinity - in other words, the algorithm fails.
i reply
use NaN and Float
sorry, i am not a native speaker, might, indeed, surely i expressed myself badly
Just a MS Windows developer... My Web Page
I understand you're not a native speaker.
Either you're being sarcastic, or you're completely missing the point...
That complexity is just part of the analysis of the algorithm.
It has nothing to do with 0 or NaN or anything hardware...
Basically I'm saying that (now, I'm just making these numbers up):
at 10,000,000 digits, it needs 100MB and 1 second
at 100,000,000 digits, it needs 2GB and 20 seconds
at 1 billion digits, it needs 50GB and 10 minutes
at 10 billion digits, it needs 5TB and 10 hours
at 100 billion digits, it needs 1000TB and 10 years
at 1 trillion digits, it needs infinite memory, and infinite time.
That's what I mean by blows up.
Basically, you get to the point where you have so many operations that no matter what you do, 53 bits of precision isn't enough, because roundoff error alone takes up 53 bits of precision.
Main Machine:
AMD FX8350 @ stock --- 16 GB DDR3 @ 1333 MHz --- Asus M5A99FX Pro R2.0 --- 2.0 TB Seagate
Miscellaneous Workstations for Code-Testing:
Intel Core i7 4770K @ 4.0 GHz --- 32 GB DDR3 @ 1866 MHz --- Asus Z87-Plus --- 1.5 TB (boot) --- 4 x 1 TB + 4 x 2 TB (swap)
 Posting Permissions
Posting Permissions




 Reply With Quote
Reply With Quote





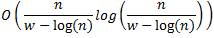



Bookmarks